Fine-tune and host Hugging Face BERT models on Amazon SageMaker

Original Source Here
The last few years have seen the rise of transformer deep learning architectures to build natural language processing (NLP) model families. The adaptations of the transformer architecture in models such as BERT, RoBERTa, T5, GPT-2, and DistilBERT outperform previous NLP models on a wide range of tasks, such as text classification, question answering, summarization, and text generation. These models are exponentially growing larger in size from several million parameters to several hundred billion parameters. As the number of model parameters increases, so does the computational infrastructure that is necessary to train these models.
This requires a significant amount of time, skill, and compute resources to train and optimize the models.
Unfortunately, this complexity prevents most organizations from using these models effectively, if at all. Wouldn’t it be more productive if you could just start from a pre-trained version and put them to work immediately? This would also allow you to spend more time on solving your business problems.
This post shows you how to use Amazon SageMaker and Hugging Face to fine-tune a pre-trained BERT model and deploy it as a managed inference endpoint on SageMaker.
Background
Hugging Face is a technology startup, with an active open-source community, that drove the worldwide adoption of transformer-based models. Earlier this year, the collaboration between Hugging Face and AWS was announced in order to make it easier for companies to use machine learning (ML) models, and ship modern NLP features faster. Through this collaboration, Hugging Face is using AWS as its preferred cloud service provider to deliver services to its customers.
To enable our common customers, Hugging Face and AWS introduced new Hugging Face Deep Learning Containers (DLCs) to make it easier than ever to train and deploy Hugging Face transformer models on SageMaker. The DLCs are fully integrated with the SageMaker distributed training libraries to train models more quickly using the latest generation of accelerated computing instances available on Amazon Elastic Compute Cloud (Amazon EC2). With the SageMaker Python SDK, you can train and deploy your models with just a single line of code, enabling your teams to move from idea to production more quickly. To deploy Hugging Face models on SageMaker, you can use the Hugging Face DLCs with the new Hugging Face Inference Toolkit. With the new Hugging Face Inference DLCs, you can deploy your models for inference with just one more line of code, or select from over 10,000 pre-trained models publicly available on the Hugging Face Hub, and deploy them with SageMaker, to easily create production-ready endpoints that scale seamlessly, with built-in monitoring and enterprise-level security.
One of the biggest challenges data scientists face for NLP projects is lack of training data; you often have only a few thousand pieces of human-labeled text data for your model training. However, modern deep learning NLP tasks require a large amount of labeled data. One way to solve this problem is to use transfer learning. Transfer learning is an ML method where a pre-trained model, such as a pre-trained ResNet model for image classification, is reused as the starting point for a different but related problem. By reusing parameters from pre-trained models, you can save significant amounts of training time and cost. BERT was trained on BookCorpus and English Wikipedia data, which contains 800 million words and 2,500 million words, respectively. Training BERT from scratch would be prohibitively expensive. By taking advantage of transfer learning, you can quickly fine-tune BERT for another use case with a relatively small amount of training data to achieve state-of-the-art results for common NLP tasks, such as text classification and question answering.
In this post, we show you how to use SageMaker Hugging Face DLC, fine-tune a pre-trained BERT model, and deploy it as a managed inference endpoint on SageMaker.
Working with Hugging Face Models on SageMaker
This sample uses the Hugging Face transformers and datasets libraries with SageMaker to fine-tune a pre-trained transformer model on binary text classification and deploy it for inference.
The model demoed here is DistilBERT—a small, fast, cheap, and light transformer model based on the BERT architecture. Knowledge distillation is performed during the pre-training phase to reduce the size of a BERT model by 40%. A pre-trained model is available in the transformers library from Hugging Face.
You’ll be fine-tuning this pre-trained model using the Amazon Reviews Polarity dataset, which consists of around 35 million reviews from Amazon, and classify the review into either positive or negative feedback. Reviews were collected between 1995–2013 and include product and user information, ratings, and a plaintext comment. It’s available under the amazon_polarity dataset on Hugging Face.
Data preparation
For this example, the data preparation is straightforward because you’re using the datasets library to download and preprocess the amazon_polarity dataset directly from Hugging Face.
The following is an example of the data:
dataset_name = 'amazon_polarity'
train_dataset, test_dataset = load_dataset(dataset_name, split=['train', 'test'])
train_dataset = train_dataset.shuffle().select(range(10000)) # We're limiting the dataset size to speed up the training during the demo
test_dataset = test_dataset.shuffle().select(range(2000))The label being set at 1 denotes a positive review, and 0 means a negative review. The following is an example of a positive review:
{'content': 'Little Slow on Review.. I only get to read at Dr Appts and other type breaks in day.Worth the read and I can understand mind set of why book is popular in war zones.I would suggest it to anyone that enjoys military reading..',
'label': 1,
'title': 'Soild Number 1 Book In Iraq and Afganastan'}The following is an example of a negative review:
{'content': 'I just received and needs a couple more clicks on my head to fit correct. And if I try to turn dial to tighten, the release is on top of dial and I keep pressing it and it gets loose again. I dont know why they designed it with points on the dial. It starts to hurt my thumb if I try to tighten. I bought this cause the light weight but sticker on helmet says 298 g the description says 255. This sucks..',
'label': 0,
'title': 'Feels heavy.'}As shown in the following visualization, the dataset is already well balanced and no further preprocessing is required.
Transformers models in general, and BERT and DistilBERT in particular, use tokenization. This means that a word can be broken down into one or more sub-words referenced in the model vocabulary. For example, the sentence “My name is Marisha” is tokenized into [CLS] My name is Maris ##ha [SEP], which is represented by the vector [101, 1422, 1271, 1110, 27859, 2328, 102]. Hugging Face provides a series of pre-trained tokenizers for different models.
To import the tokenizer for DistilBERT, use the following code:
tokenizer_name = 'distilbert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
This tokenizer is used to tokenize the training and testing datasets and then converts them to the PyTorch format that is used during training. See the following code:
# Helper function to get the content to tokenize
def tokenize(batch):
return tokenizer(batch['content'], padding='max_length', truncation=True)
# Tokenize
train_dataset = train_dataset.map(tokenize, batched=True, batch_size=len(train_dataset))
test_dataset = test_dataset.map(tokenize, batched=True, batch_size=len(test_dataset))
# Set the format to PyTorch
train_dataset.rename_column_("label", "labels")
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
test_dataset.rename_column_("label", "labels")
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
After the data is processed, you upload it to Amazon Simple Storage Service (Amazon S3) for training:
import botocore
from datasets.filesystems import S3FileSystem
# Upload to S3
s3 = S3FileSystem()
s3_prefix = f'samples/datasets/{dataset_name}'
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path,fs=s3)
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path,fs=s3)
print(f'Uploaded training data to {training_input_path}')
print(f'Uploaded testing data to {test_input_path}')Training with the SageMaker Hugging Face Estimator
You need a Hugging Face Estimator in order to create a SageMaker training job. The Estimator handles end-to-end SageMaker training. In an Estimator, you define which fine-tuning script should be used as entry_point, which instance_type should be used, and which hyperparameters are passed in.
The hyperparameters consist of the following:
- Number of epochs
- Batch size
- Model name
- Tokenizer name
- Output directory
The training script uses the model name and tokenizer name to download the pre-trained model and tokenizer from Hugging Face:
huggingface_estimator = HuggingFace(entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
hyperparameters = hyperparameters)
When you create a SageMaker training job, SageMaker takes care of the following:
- Starting and managing all the required compute instances for you with the
huggingfacecontainer - Uploading the provided fine-tuning script
train.py - Downloading the data from
sagemaker_session_bucketinto the container at/opt/ml/input/data
Then, it starts the training job by running the following command:
/opt/conda/bin/python train.py --epochs 10 --model_name distilbert-base-cased --token_name distilbert-base-cased--train_batch_size 1024The hyperparameters you define in the Estimator are passed in as named arguments.
SageMaker provides useful properties about the training environment through various environment variables, including the following:
- SM_MODEL_DIR – A string that represents the path where the training job writes the model artifacts to. After training, artifacts in this directory are uploaded to Amazon S3 for model hosting.
- SM_NUM_GPUS – An integer that represents the number of GPUs available to the host.
- SM_CHANNEL_XXXX – A string that represents the path to the directory that contains the input data for the specified channel. For example, if you specify two input channels in the Estimator’s
fitcall, namedtrainandtest, the environment variablesSM_CHANNEL_TRAINandSM_CHANNEL_TESTare set.
Start the training using the fit function:
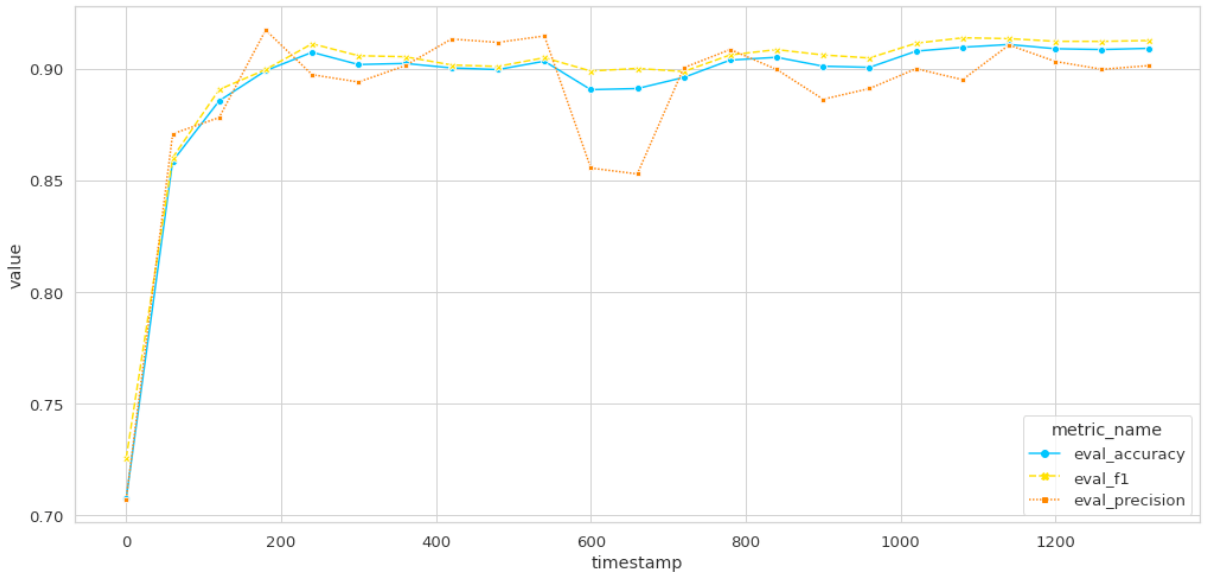
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path}, wait=False, job_name=training_job_name )When the training is finished, you can draw the metrics on a graph.
Architecture for serving Hugging Face model inference on SageMaker
The Hugging Face Inference Toolkit for SageMaker is an open-source library for serving Hugging Face transformer models on SageMaker. It utilizes the SageMaker Inference Toolkit for starting up the model server, which is responsible for handling inference requests. The SageMaker Inference Toolkit uses Multi Model Server (MMS) for serving ML models. It bootstraps MMS with a configuration and settings that make it compatible with SageMaker and allow you to adjust important performance parameters, such as the number of workers per model, depending on the needs of your scenario.
MMS is an open-source framework for serving ML models with a flexible and easy-to-use tool for serving deep learning models trained using any ML/DL framework. You can use the MMS server CLI, or the preconfigured Docker images, to start a service that sets up HTTP endpoints to handle model inference requests. It also provides a pluggable backend that supports a pluggable custom backend handler where you can implement your own algorithm.
You can deploy fine-tuned or pre-trained models with Hugging Face DLCs on SageMaker using the Hugging Face Inference Toolkit for SageMaker without the need for writing any custom inference functions. You can also customize the inference by providing your own inference script and override the default methods of HuggingFaceHandlerService. You can do so by overriding the input_fun(), output_fn(), predict_fn(), model_fn() or transform_fn() methods.
The following diagram illustrates the anatomy of a SageMaker Hugging Face inference endpoint.

As shown in the architecture, MMS listens on a port, accepts an incoming inference request, and forwards it to the Python process for further processing. MMS uses a Java-based front-end server that uses a NIO client server framework called Netty. The Netty framework provides better throughput, lower latency, and less resource consumption; minimizes unnecessary memory copy; and allows for a highly customizable thread model—a single thread, or one or more thread pools. You can fine-tune the MMS configuration, including number of Netty threads, number of workers per model, job queue size, response timeout, JVM configuration, and more, by changing the MMS configuration file. For more information, see Advanced configuration.
The MMS forwards the inference request to the SageMaker Hugging Face provided default handler service or a custom inference script. The default SageMaker Hugging Face handler uses the Hugging Face pipeline abstraction API to run the predictions against the models by using the respective underlying deep learning framework, namely PyTorch or TensorFlow. Depending on the type of EC2 instance configured, the pipeline uses CPU or GPU devices to run the inference and return the response back to the client via MMS front-end server. You can configure the environment variables to fine-tune the SageMaker Hugging Face Inference Toolkit. In addition, you can fine-tune the standard Hugging Face configuration.
Deploy the fine-tuned BERT model for inference
To deploy your fine-tuned model for inference, complete the following steps:
- Define a Hugging Face model using the following code:
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = sagemaker.huggingface.HuggingFaceModel(
env={ 'HF_TASK':'sentiment-analysis' },
model_data=huggingface_estimator.model_data,
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.6.1", # transformers version used
pytorch_version="1.7.1", # pytorch version used
py_version='py36', # python version
)- Deploy an inference endpoint for this fine-tuned model:
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge"
)- After deployment, test the model with the following code:
data = {
"inputs": "This is a very good product!"
}
# request
predictor.predict(data)The result is positive (LABEL_1) at 99.88%:
[{'label': 'LABEL_1', 'score': 0.9988064765930176}]The complete solution is available in the GitHub repo.
Clean up
After you’re finished experimenting with this project, run predictor.delete_endpoint() to remove the endpoint.
Conclusion
This post showed how to fine-tune a pre-trained transformer model with a dataset using the SageMaker Hugging Face Estimator and then host it on SageMaker using the SageMaker Hugging Face Inference Toolkit for real-time inference. We hope this post allows you to quickly fine-tune a transformer model with your own dataset and incorporate modern NLP techniques in your products. The complete solution is available in the GitHub repo. Try it out and let us know what you think in the comments!
About the Authors
 Eddie Pick is a Senior Startup Solutions Architect. As an ex co-founder and ex CTO his goal is to help startups to get rid of the undifferentiated heavy lifting to be able spend as much time as possible on new products and features instead
Eddie Pick is a Senior Startup Solutions Architect. As an ex co-founder and ex CTO his goal is to help startups to get rid of the undifferentiated heavy lifting to be able spend as much time as possible on new products and features instead
 Dhawalkumar Patel is a Startup Senior Solutions Architect at AWS. He has worked with organizations ranging from large enterprises to startups on problems related to distributed computing and artificial intelligence. He is currently focused on machine learning and serverless technologies.
Dhawalkumar Patel is a Startup Senior Solutions Architect at AWS. He has worked with organizations ranging from large enterprises to startups on problems related to distributed computing and artificial intelligence. He is currently focused on machine learning and serverless technologies.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/08/31/fine-tune-and-host-hugging-face-bert-models-on-amazon-sagemaker/


