Fully Explained DBScan Clustering Algorithm with Python
Original Source Here
Fully Explained DBScan Clustering Algorithm with Python
Unsupervised learning in machine learning on density-based clusters
In this article, we will discuss the machine learning clustering-based algorithm that is the DBScan cluster. The approach in this cluster algorithm is density-based than another distance-based approach. The other cluster which is distance-based looks for closeness in data points but also misclassifies if the point belongs to another class. So, density-based clustering is suited in this kind of scenario. The cluster algorithms come in unsupervised learning in which we don’t rely on target variables to make clusters.
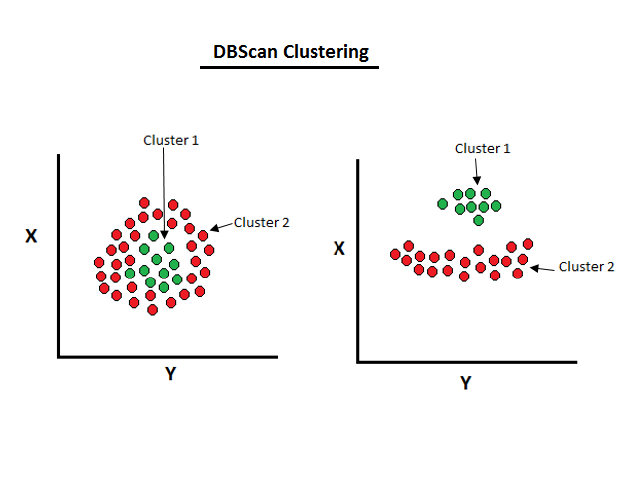
In a cluster, the main concern is on maximum dense connected points. The density-based clustering can be useful in arbitrary shapes even with noise.
The working function of the density-based cluster is shown below:
- We select a random data point.
- Then it will take two arguments to check the density around that point. First, it will make a radius around that point and second, it will check the minimum point in that radius.
- If the point checks truly with minimum points then it will make the cluster of that point and move forward to other points and if not then it will treat it as an outlier.
- The DBSCAN methods have two parameters of these i.e. eps(epsilon) to make a radius and min_samples to check minimum points.
- The default value of these parameters is 0.5 and 5 respectively.
The distance measurement to find the neighbors is a very important step and distance function.
There is another metric to choose the distance function. The default value of this metric is euclidean but it can be a string or callable. If we choose string or callable then we should consider the pairwise distance method in metric.
There is another parameter called algorithm that used for searching neighbors in machine learning as shown below:
- Brute Force search: It is fine with small data sets and provides fast searching of the neighbors and not feasible when the data set grows.
- K-D and Ball tree: One level above brute search. This searching is based on association and done in structured tree type. While the ball tree is useful in high dimensions of features.
The leaf size parameter is used in KD and ball tree scenario and the default value is 30. But it is not so much feasible because it makes speed slower and takes memory to save a tree.
To saves, memory constraint researchers go for OPTICS-based clustering.
Let’s do a DBSCAN cluster with python
Import the necessary libraries
# DBSCAN Clustering# Importing the libraries
import numpy as np
import pandas as pd
Read the dataset with the pandas’ read method.
# Importing the dataset
dataset = pd.read_csv('Mall_Customers.csv')
X = dataset.iloc[:, [3, 4]].values
Views of the data set.
Import the clustering algorithm from sklearn
# Using the elbow method to find the optimal number of clusters
from sklearn.cluster import DBSCAN
dbscan=DBSCAN(eps=3,min_samples=4)
Now, fit the model.
# Fitting the modelmodel=dbscan.fit(X)labels=model.labels_print(labels)
We see the labels show the “-1” value also and it means that it is an outlier i.e. does not belong to any clusters. To make core points.
#identifying the points which makes up our core points
sample_cores=np.zeros_like(labels,dtype=bool)sample_cores[dbscan.core_sample_indices_]=True
To find the number of clusters
#Calculating the number of clustersn_clusters=len(set(labels))- (1 if -1 in labels else 0)
print(n_clusters)#output:
9
The above code shows the total number of clusters. To print the score of the cluster
print(metrics.silhouette_score(X,labels))#output:
-0.1908319132560097
The metric score comes to be negative and it means that the samples are assigned to the wrong cluster. The score comes in between “1” to “-1” where “1” indicates good values and “-1” indicates the worst value.
Conclusion:
The DBSCAN clustering is good for the arbitrary shape of clusters. It is also robust in the case of outliers. This algorithm is useful in anomaly detection and satellite images.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/02/26/fully-explained-dbscan-clustering-algorithm-with-python/

