Docker crash course for Machine Learning Engineers and Data Scientists — Part 1
Original Source Here
Docker crash course for Machine Learning Engineers and Data Scientists — Part 1
As a Senior Solutions architect working with Databricks, I work with some of our biggest enterprise customers and provide them with best practices on scaling ML model deployments.
Interestingly a common scenario for deploying ML models is as a REST endpoint in a scalable manner. Here Docker comes in. People who are not coming from the DevOps background find it hard to wrap their heads around Docker.
This article is the first part of a multipart series. In this article, I will provide a gentle introduction to Docker and introduce some core concepts. I will share end-end code examples of deploying various ML and Deep Learning models using Docker in the later parts.
At the end of this series, I will go over how Databricks and integrated MLFlow abstracts all the complexity of maintaining and managing your own Docker images for ML models and simplify MLOps.
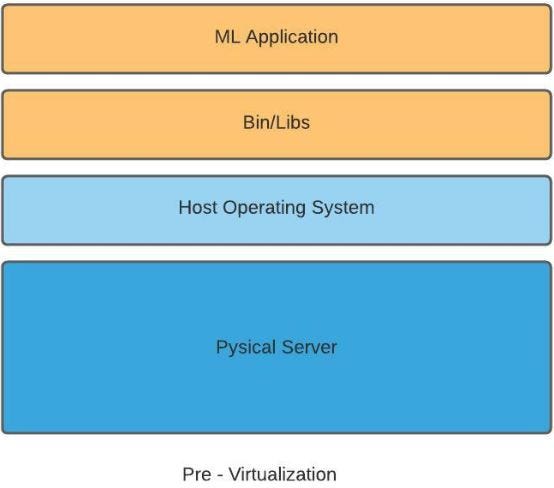
Before we understand Docker, we need to understand the challenges with ML deployments and Hypervisor-based Virtualization at a high level.
What are the challenges with ML deployments?
Traditionally most ML development in organizations starts with Data Scientists working on their laptops. Data Scientists have their own set of tools and libraries installed on their local(Dev) environment with specific hardware configurations and Operating systems.
Once the initial model is trained and tested by the Data Scientist locally, the model code is handed over to another team, QA, to deploy and test out in the QA environment. Suppose the organization is not using any virtualization. In that case, each server in the QA environment will run only one ML application. QA team’s environment may have a completely different configuration of physical machines, the installed OS, and libraries than the Data Scientists local environment.
There are a couple of challenges with this approach:
- Huge TCO (total cost of ownership): A physical machine needs to be bought or rented out upfront at a data center. The commercial server’s price is very high, and we may not utilize the entire CPU and RAM on the machine.
- Slow Deployment: The process of purchasing/renting hardware and setting them up could take a long time, sometimes in months.
- Difficulty to Migrate Applications: It will be painful to migrate applications to and from one company server, say IBM to Dell. A large amount of effort will be needed to make sure the network and other configurations are appropriately set.
This is where Hypervisor-based virtualizations help.
So what is the Hypervisor-based Virtualization technique?
In Hypervisor-based Virtualization, a new layer software layer is introduced on top of the underlying OS that allows us to install multiple virtual machines on the same underlying physical server. Each virtual machine has a different Operating system. This approach enables installing multiple OS, say Ubuntu, on one of the Guest OS and Debian on the other. Each of these virtual machines can then run different ML Applications.
Some popular Hypervisor providers include VMware and Virtual Box. As more and more companies are migrating to the cloud environment, we don’t need to reserve hardware and install Hypervisor on them like before. Cloud providers provide us the option to rent out VM’s on-demand directly.
There are some obvious benefits to this approach:
- Cost efficiency: Each physical machine is divided into multiple VM’s, and each of the VM’s can use only their designated CPU, Memory, and Storage resources. Organizations pay only for the computing, storage, and other resources used, and there are no huge upfront costs. It’s more of a pay-as-you-go model.
- Easier to scale: As the VM’s are deployed in the cloud environment, it’s much more accessible to allocate more VMs than ordering and configuring more physical servers. It’s an on-demand click and deploys model. Our ML applications can scale in mere minutes and not weeks.
However, this approach still has some limitations:
- Kernel Resource Duplication: Each of the virtual machines still needs a Guest OS to be installed. Each Guest OS has its own set of drivers, memory management, daemons, and more. If we talk just about Linux OS, then we are talking about Kernel. If we have three VMs running on one physical server, we have three Guest OS and three Kernels. Even though each of the Kernels is separate, we are still copying and replicating the core functionality of Linux OS. This is still not an efficient use of resources.
2. Application Portability Issues: VM portability is still a work in progress. Suppose you want to transfer VM’s across different hypervisors. In that case, it’s still a challenge, and any progress is still at the early stages.
Imagine a scenario when an ML model fails to execute after being promoted to the QA environment. In this scenario, it becomes increasingly difficult to debug the issue as the ML model code works correctly in the development environment and not in the QA environment. This may be happening because of compatibility issues between the libraries installed on the Dev and QA environments.
The ML application being promoted may be reliant on libraries that themselves rely on the underlying Hypervisor, hardware, and OS version of the VMs/Servers.
This is the problem Docker provides a solution to.
Docker
Docker is a widely adopted implementation of Container-based virtualization technology.
Underneath, we have our physical server or a VM. On top of the server, we run the Operating System. Then we install software called the Container Engine that allows us to run multiple guest instances called containers. We install our ML application and libraries the application depends on in the container.
The critical difference between hypervisor-based virtualization and Container-based virtualization is the replication of the Kernels. In the Hypervisor-based virtualization, each ML Application runs in its VM and copy of the Kernel, and virtualization happens at the hardware level.
In the Container-based virtualization, we have only one Kernel, which will supply the different binaries and libraries version to the ML applications running in their isolated container. So all the containers will share the same base runtime Kernel that is the Container Engine. The virtualization happens at the OS level, and containers share the host’s OS, which is much more efficient and lightweight.
What is the advantage of running ML Applications in their containers and not a single VM?
This is where I would like to introduce the concept of Runtime Isolation. Most ML applications may be running on a different version of Scala, Python, or R apart from individual library versions. It will be tough to make the two applications run without any conflicts in the same VM. Containers can easily isolate the runtime environments and provide resolution to this problem.
Imagine the case where one ML application uses Python 2, and the other ML application utilizes Python 3. Using containers, we can deploy both these applications in an isolated fashion on the same host machine.
Here are the benefits of this approach:
- Cost-Efficient: Container-based virtualization does not create an entire virtual machine. Instead, only the required components are packaged inside the container with the ML application. This makes the containers consume less CPU, RAM and, storage space than VM’s, which means we can have more containers running on one physical machine than VM’s.
- Faster Deployment Speeds: Since containers house the minimal requirements for running the ML Application, it speeds up the process to deploy any change than a VM.
- Portability Guarantee: As containers are independent and self-sufficient bundles of an application, they can be run across machines without compatibility issues.
Conclusion
This article covered how Docker simplifies ML Application deployment and is a powerful tool for Data Scientists and ML Engineers to have in their toolbox.
MLFlow integrated with the Databricks environment makes it super easy for Data scientists and ML Engineers to focus on implementing the ML Algorithm to solve the business problem.
With one command in MLFlow, you can create a light web application wrapper around your ML Model and create a Docker container with all the dependencies. More to come on this in the coming articles.
Please drop a note if you have any questions.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/07/25/docker-crash-course-for-machine-learning-engineers-and-data-scientists%e2%80%8a-%e2%80%8apart-1/


