Transformer with OCR — From molecule to manga
Original Source Here
I have recently joined Kaggle competition, Bristol-Myers Squibb — Molecular Translation (BMS competition). Unfortunately, I missed solo gold, but I could get some interesting findings, which are also generally useful for common OCR tasks. I would like to share them on this post by taking up Manga OCR as a subject.
About BMS competition
In BMS competition, participants predict InChI text, which is uniquely defined for each molecule, from printed molecule image.
Some people call it as image captioning. Others call it as OCR. Anyway, we predict a sequence from an image.
Top solutions are listed here. The most commonly used architecture is a typical transformer encoder-decoder model, which is a kind of combination of Vision Transformer and BART. It seems that Swin Transformer has shown good performance as an encoder.
General OCR and Deep Learning
The typical encoder-decoder Transformer worked quite well in BMS competition. It is a kind of OCR task. So, my question is “How well it works in other general OCR tasks?”.
As far as I researched, it seems that CRNN architecture is used for OCR tasks usually. In CRNN, CNN like ResNet is used as an encoder and LSTM is used as a decoder. Actually, this architecture was used in BMS competition too. It has shown good performance, but the best was the Transformer.
I pick up Manga OCR as an example task to investigate it further.
Manga OCR
Manga is an interesting area as a perspective of rapidly growing innovation of Deep Learning (DL).
This figure below shows what DL can do for Manga.
Furthermore, some companies try automated color painting to mono color Manga images.
In this post, I just pick up OCR part, but I believe that Manga market will face big changes in future, because of such upcoming innovations (and it’s not only for Manga).
Dataset and splitting
Manga109 is a published dataset for academic research purpose. The subset of Manga109, which is called as Manga109s containing 87 titles of Manga, is also available for non-academic purpose. All of my experiments are conducted with Manga109s.
Before dive into modeling, data splitting strategy should be described. Mainly, there are two possible ways of splitting.
- Vertical Splitting
- Horizontal Splitting
Vertical splitting is useful, when we want to know how well our model performs with new titles. On the other hand, Horizontal split can be used to evaluate new volume with existing titles. It’s expected that the score will be low in Vertical split. For sure, it does not mean that Vertical split is bad. It’s just a difference about what we want to evaluate.
Training and Results
Manga109s has about 0.1 M annotated texts. It’s not so small, but not so much. In this situation, pre-training with large amount of synthesized text-img pairs will definitely help to improve the models. As Transformer models are data hungry, it’s interesting to know how much it can be improved.
I used CC-100 Japanese corpus and 800 font files, which are from about 100 unique font styles, to generate synthesized Japanese text images.
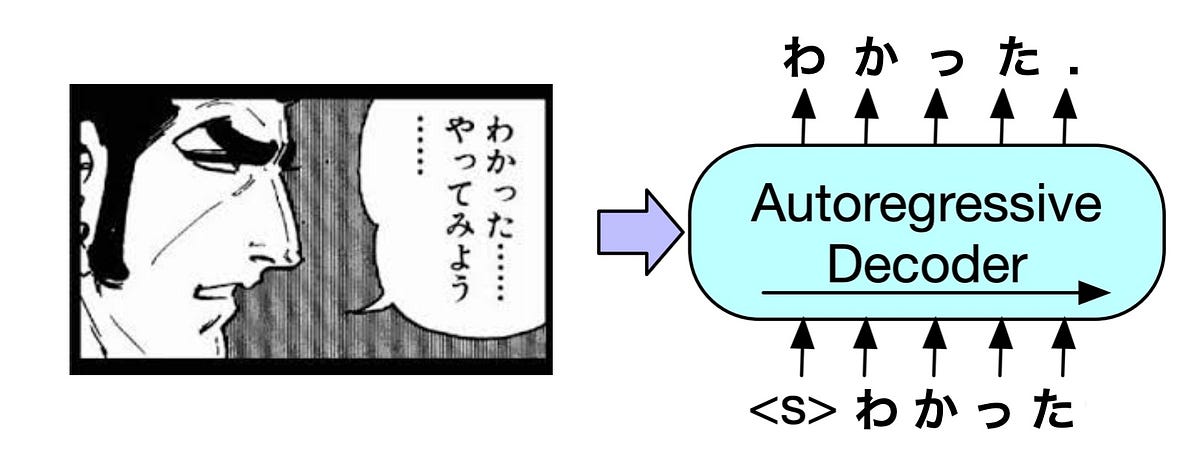
Recent study (Hongfei Xu et al. Mar 2020) has shown that the budget for decoder should be transferred to encoder in translation task. It makes it possible for Auto-Regressive model to run faster in inference without losing prediction performance. Though it’s about translation, I used same idea for OCR and used only 2 decoder layers.
Some summary points on the table above.
- Pre-training significantly improves acc.
- Transformer model shows almost similar acc with CRNN.
- Transformer model (used here) is faster than CRNN.
- Larger vision model and longer pre-training shows significant improvements.
The horizontal split shows better acc than the vertical split, but BERT score is not so different. It makes sense. Model can know well about proprietary noun such as “Son Goku” in horizontal split, but even if it was replaced by “Son Gohan”, BERT score won’t be changed so much.
After ensemble, I also measured the performance by using oof (5 CV). It achieves acc=0.825.
Error analysis
At a glance, there are many errors about repeating characters.
pred: う ひ ゃ ― ― ― ― ― ~ っ!!?
true: う ひ ゃ ― ~ っ ~ ~!!?
This case is not clear even for human to say how many times “―”should be repeated. I can find 5724 errors (28% in false predictions) like this. When I ignore such errors, acc becomes 0.87.
After ignoring them, I can find relatively many incorrect labels. Actually, the case above is also incorrect label, because“~” should appear once.
pred: あ ん た が ぼ く ら を 置 い て 行 っ ち ま う か ら だ よ
true: あ ん た が ほ く ら を 置 い て 行 っ ち ま う か ら だ よ
“ほ” on true text is wrong in this case.
I roughly estimated the number of such label noises. It seems that almost half of remaining errors are from this reason. When I ignore them, substantially, acc becomes 0.93.
Let’s take a look at some other real errors.
pred: お は よ う ご ざ い ま す
true: お は よ う ご ざ い ま す ―
Prediction misses last “―”. However, I think that model performs really well, though it is hand-written and horizontal 2 lines text in this case.
pred: な の に 帯 刀 さ ん に は と き め か な い 好 き だ け ど 恋 じ ゃ な い……
true: な の に 帯 刀 さ ん に は と き め か な い 好 き だ け ど………… 恋 じ ゃ な い……
It misses long repeated “.” in the middle.
pred: 私 は 今 二 人 で や っ て る よ
true: 私 は 今 一 人 で や っ て る よ
It misunderstands “一 人” with “二 人”. Background might affect it. It also notable that predicted sentence is still valid sentence.
Conclusion
I have shown how well Transformer model works in OCR task. It performs as well as, or better than, commonly used CRNN architecture. Especially, after pre-training with various fonts and large corpus, it shows nearly perfect result in Manga OCR task, though Manga OCR is difficult task that contains various styles of texts.
Here are some possible ideas for further improvement.
- Longer pre-training
- Larger model
- Augment background in pre-training
- Char masking in pre-training
- Fixing label noise
CC-100 JA has about 400 M data samples, but I used only 90 M in this experiment. Larger model would be also definitely better. Swin-S that I used is a small model.
Some false samples indicate that current model is a little weak with noisy background. Augmented background in pre-training will help it.
Char masking is a similar idea with the way to train BART. It randomly masks some characters on an image. When I tried it a little with short pre-training, the result did not change so much. However, I guess that it works, if it’s done with longer training and larger model.
The pre-trained model here can be fine-tuned to any Japanese OCR tasks. It would work in other tasks as well as Manga task I have shown here.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/07/01/transformer-with-ocr%e2%80%8a-%e2%80%8afrom-molecule-to-manga/


