Deep Learning Tutorial (Part 1): Basics
Original Source Here
Deep Learning Tutorial (Part 1): Basics
Deep Learning is a subset of Machine Learning. While Machine Learning generally can be described as any approach to “learn an algorithm without explicit programming”, Deep Learning extracts patterns from data using neural networks. There are multiple speculative reasons why Deep Learning got popular recently:
- the availability of large data sets or at least more possibilities to collect and store them easily
- the increasing performance of GPUs
- the development and availability of open source frameworks such as Tensorflow (realeased 2015 by Google) and PyTorch (released 2016 by Facebook)
There are also many use cases for Deep Learning such as object recognition, face recognition, autonomous driving, and Natural Language Processing (NLP) which are hard to solve using traditional approaches. But despite the wide range of possibilities to use Deep Learning, it is not an universal solution. Since Deep Learning uses neural networks we focus on them first.
Deep Neural Networks
A deep neural network (DNN) consists of neurons which are grouped in layers including an input layer and an output layer. The layers between these two layers are called hidden layers. There are multiple types of layers like fully-connected layers, convolutional layers and residual layers, which differ in how the neurons are connected to each other.
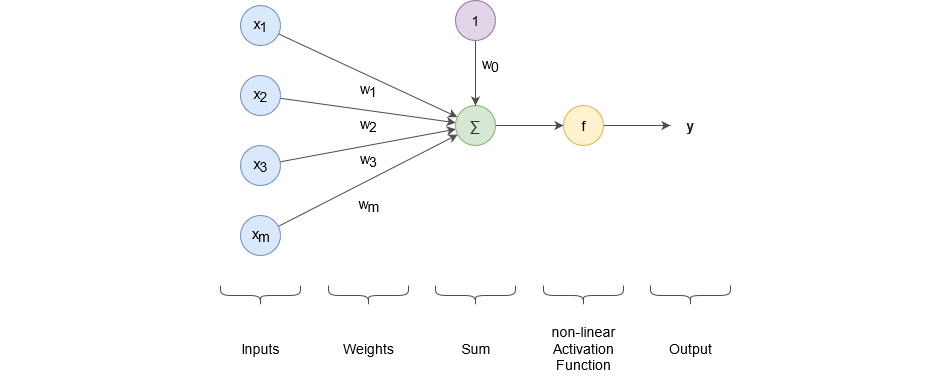
Lets zoom in into the functionality of one neuron:
The functionality of a neuron can be described as the summation
of all weighted input values (x_1 .. x_m) and a bias w_0 and then applying the non-linear activation function f to get an output y. Depending on the weights and bias, the neuron behaves differently with respect to the input signals. This is exactly the information that has to be gained during the training of a model. The non-linear activation function serves a special purpose. It introduces non-linearity into the model. In the past, the sigmoid function was usually used for this task:
Currently, the ReLU function is used more often. This is mainly due to the simple computability with similarly good results.
This means that the neural network consists of a large number of neurons where usually one neuron receives input signals from the previous layer (left) and generates an output signal (to the right). The size of this network and therefore the number of neurons depends on the respective task.
For example, a neural network that is used to classify gray images with a resolution of 128×128 pixels must also have at least 128×128 neurons in the input layer. One possible task for such a network would be detecting whether there are dogs or cats in the images. This is a typical supervised learning use case. Supervised means, that the network is trained using labeled data (pairs of input data and the correct output called label). This means that for the task “distinguish dog from cat” it would be necessary to collect as many pictures of dogs and cats as possible and label them for training.
The data would now typically be split into a relatively large training dataset and a smaller test dataset. The training data is used to train the model and the test data set is used to determine its accuracy on data that is unknown to the model.
Let’s talk a little bit about the intuitive idea behind the approach: when you are shown a picture, you can tell relatively quickly whether an object in the picture is a dog or a cat. When you try to justify this decision, you find it probably relatively difficult, because you have simply looked for known patterns. A suitably large neural network can reproduce this functionality. Theoretically, it only has to be trained with enough data and needs to have enough neurons to be able to represent the function.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/06/23/deep-learning-tutorial-part-1-basics/


