DINO: Emerging Properties in Self-Supervised Vision Transformers Summary
Original Source Here
DINO: Emerging Properties in Self-Supervised Vision Transformers Summary
DINO, a new self supervised system by Facebook AI, is able to learn incredible representations from unlabeled data. Below is a video visualising it’s attention maps and we see the model was able to automatically learns class-specific features leading to accurate unsupervised object segmentation. It was introduced in their paper “Emerging Properties in Self-Supervised Vision Transformers”
Here’s a summary of how it works 👇
Networks:
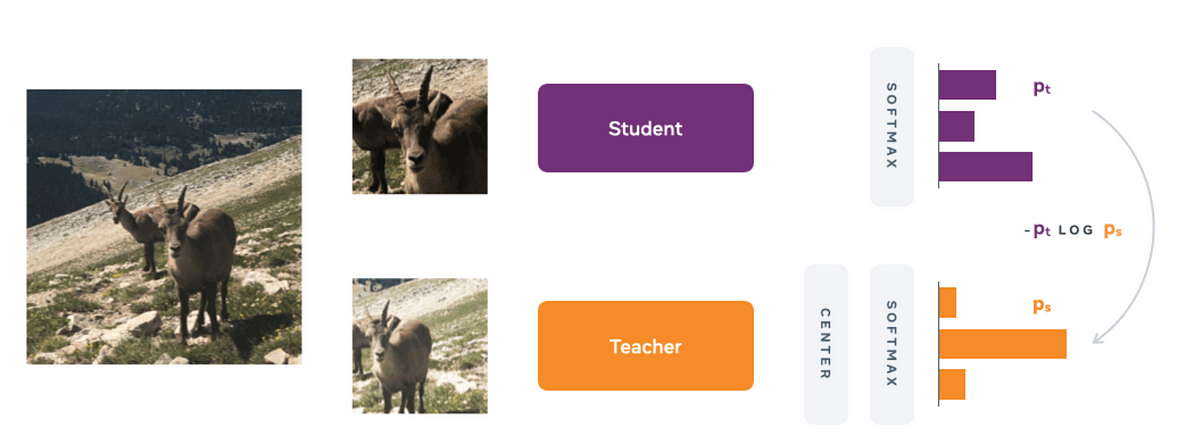
The network learns through a process called ‘self-distillation’. There is a teacher and student network both having the same architecture, a Vision Transformer(ViT).
The teacher is a momentum teacher which means that it’s weights are an exponentially weighted average of the student’s. The momentum teacher was introduced in the paper “Momentum Contrast for Unsupervised Visual Representation Learning” in order to prevent mode collapse when the teacher and the student are the same and output the same embeddings regardless of the input.
The update rule for the teacher’s weights are:
with λ following a cosine schedule from 0.996 to 1 during training in this paper.
Data:
As is common in self-supervised learning, different crops of one image are taken. Small crops are called Local views( <50% of the image) and large crops( >50% of the image) are called Global views.
All crops are passed through the student while only the global views are passed through the teacher. This encourages “local-to-global” correspondence, training the student to interpolate context from a small crop. See Fig 1.
Random augmentations of color jittering, Gaussian blur and solarization are also applied on the views to make the network more robust.
Loss
The teacher and student each predict a 1-dimensional embedding. A softmax along with cross entropy loss is applied to make student’s distribution match the teacher’s
Softmax is like a normalisation, it converts the raw activations to represent how much each feature was present relative to the whole. eg) [-2.3, 4.2, 0.9 ,2.6 ,6] ->[0.00 , 0.14, 0.01, 0.03, 0.83] so we can say the last feature’s strength is 83% and we would like the same in the student’s as well. We want proportions to be the same, not the raw value of the features.
The cross-entropy loss tries to make the two distributions the same just as in knowledge distillation.
This can also be seen as a made up classification problem. We are asking our network make up a classification problem such that the network can learn meaningful global representations from local views.
Centering and Sharpening
There are two forms of collapse: regardless of the input, the model output is always the same along all the dimensions(i.e same output for any input) or dominated by one dimension. Centering and Sharpening aim to prevent both these.
Centering: The teacher’s raw activations have the their exponentially moving average subtracted from them.
Logits = Logits-Logits_mean
This means that activations must be sometimes positive when they are above their mean and sometimes negative when they are below. This prevents any one feature from dominating as the mean will be somewhere in the middle of the range. And we know that softmax gives very low values to negative numbers and high values to positive ones.
Sharpening: Sharpening is the same as applying a temperature to the softmax to artificially make the distribution more peaked, i.e exaggerate small differences so that there is one or some high values and some low values. This prevents all the activations from being the same value as small differences are exaggerated. This acts in synergy with centering which keeps changing which activations are high. Sharpening also helps the student get a stronger signal which features it should increase.
DINO Psedudocode:
Summary:
A Student ViT learns to predict global features in an image from local patches supervised by the cross entropy loss from a momentum Teacher ViT’s embeddings while doing centering and sharpening to prevent mode collapse …. Wow thats a lot of jargon!
Relevant Links for Emerging Properties in Self-Supervised Vision Transformers:
GitHub: https://github.com/facebookresearch/dino
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/05/10/dino-emerging-properties-in-self-supervised-vision-transformers-summary/


