Deep Learning
Original Source Here
Why LSTM more useful than RNN in Deep Learning?
Memory storage capacity approach in deep neural networks
Introduction
This article is a sequel to the previous article on recurrent neural networks. The LSTM model overcomes the issues in the recurrent neural networks of memory storage of the previous state and decides the prediction based on it. It means the vanishing gradient problem due to this we cannot train the network properly this causes the recurrent neural network does not retain the long term sequences in the memory.
The special thing in LSTM is that it achieves long-term dependency and it process the information to keep and discard facility. All these conditions are done with the help of three gates i.e. output gate, input gate, and forget gate.
The difference between recurrent neural networks and long-short term memory is that RNN has a hidden state to store information and making predictions. On the other hand, the LSTM has the hidden state broken into cell state and hidden state.
1. The cell state is an internal memory to store all the
information.
2. The hidden state is used for operations for the output.
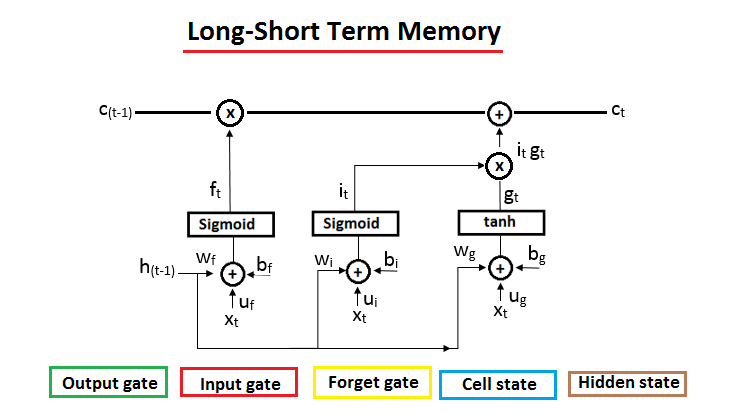
The basic architecture of LSTM is shown below:
The basic architecture consists of the previous cell state, cell state, previous hidden state, and hidden state. The subscript is the t and (t-1) are state at the time.
The forget gate, input gate, and output gate are modulating the input signal. These gates are modifying the information stored in the previous cell state with some operations that modifies the result as in cell state. The output gate transfer the information stored in the cell state to the output state y(t).
Working of these gates
Forget Gate
This gate is responsible for deciding what information should remove from the cell state.
For example:
Indian is a beautiful country. I live in India.
Norway is also a beautiful country.
India is a subject in the first sentence but when we talk about Norway, this becomes the subject. In LSTM the forget gate is recognized that the subject is changed to Norway and remove India as a subject. This type of intelligent behavior is done with the help of forget gate.
We can see the formula of the forget gate that is the function of the input signal and previous hidden state with the multiplication of weight matrices u(f), w(f), and b(f). These all units are modulated by the sigmoid function sigma. The value in the forget gate is in the range of “0” to “1” i.e. the information with the value “0” will be removed and the information with the value “1” will be retained.
Input Gate
This gate is responsible for deciding what information should store in the cell state.
For example:
Indian is a beautiful country. I live in India.
Norway is also a beautiful country.
In the above example, the forget is used to which information to be removed and chooses the new subject “Norway”. Now the work of the input gate to store this new subject to the cell state c(t-1).
The formula of the input data is shown below that is the function of the input signal and previous hidden state with the multiplication of weight matrices u(i), w(i), and b(i). These all units are modulated by the sigmoid function sigma. The value in the input gate is in the range of “0” to “1” i.e. the information with the value “0” will not be stored and the information with the value “1” will be stored/updated.
Output Gate
This gate is responsible for which information should be chosen from the cell state c(t-1) to give as an output y.
For example:
Indian is a beautiful country. I live in India.
Norway is also a beautiful country. You must visit the capital of .........
In the above example, the output has used that information in the hidden state will be passed or not. The output gate will decide the subject to be filled in the blanks i.e. Norway.
The formula of the output date is shown below that is the function of the input signal and previous hidden state with the multiplication of weight matrices u(0), w(0), and b(0). These all units are modulated by the sigmoid function sigma. The value in the input gate is in the range of “0” to “1” i.e. the information with value “0” does not pass the hidden state to the output and the information with value “1” will pass the hidden state to the output.
Candidate State
This state is responsible for add the new information or updating the cell state.
The formula of this state is shown below:
The above formula now has parameterized function “tan hyperbolic”.
The state is used to hold the information that is controlled by i(t) with the multiplication operator. If the value of the i(t) is “0” then no information will pass to the cell state and the value of the i(t) is “1” then the g(t) information will add to the cell state line.
Conclusion:
This is the basic idea behind the working flow of the LSTM algorithm in deep learning. The flow of information from the gates and candidate state changes the cell state output c(t).
I hope you like the article. Reach me on my LinkedIn and twitter.
Recommended Articles
1. NLP — Zero to Hero with Python
2. Python Data Structures Data-types and Objects
3. Exception Handling Concepts in Python
4. Principal Component Analysis in Dimensionality Reduction with Python
5. Fully Explained K-means Clustering with Python
6. Fully Explained Linear Regression with Python
7. Fully Explained Logistic Regression with Python
8. Differences Between concat(), merge() and join() with Python
9. Data Wrangling With Python — Part 1
10. Confusion Matrix in Machine Learning
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/05/15/deep-learning-8/


