Word2Vec Research Paper Explained
Original Source Here
Word2Vec Research Paper Explained
An Intuitive understanding and explanation of the word2vec model.
We know what is Word2Vec and how word vectors are used in NLP tasks but do we really know how they are trained and what were the previous approaches for training word vectors. Well, here is an attempt to explain my understanding about the Word2Vec research paper [T. Mikolov et al.]. You can find the research paper here.
1. Introduction
In many NLP applications, words are represented as one-hot encoding which don’t capture the relationship between them. The reason of choosing one-hot encoding is due to
“simplicity, robustness and observation that simple models trained on huge amounts of data outperform complex systems trained on less data.” [T. Mikolov et al.]
An example of simple model could be N-gram model. These models are the Markov models with the assumption that word at i-th position depends on the word history from i-(n-1) words until (i-1) word. It’s basically frequency based approach derived from the training corpus. But these simple models require high quality of the training data which is often not available and they don’t generalise well for unseen data.
However with the improvement in the machine learning domain, complex algorithms trained on much larger datasets perform better than the simpler models.
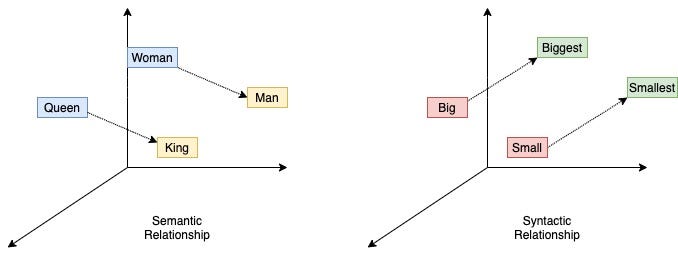
The Word2vec model captures both syntactic and semantic similarities between the words. One of the well known examples of the vector algebraic on the trained word2vec vectors is
Vector(“King”)-Vector(“Man”)= Vector(“Queen”)-Vector(“Woman).
2. Previous approaches for vector representation of words
This section is focussed on the earlier approaches for vector representation of the words using neural networks.
2. 1 Neural Network Language Model (NNLM) [Bengio, Yoshua et al.]
This is a two step language model which consists of a linear projection layer for word embeddings and a non-linear hidden layer followed by output layer. Both the word vectors and the language model are trained simultaneously in the NNLM.
The NNLM model consists of input, projection, hidden and output layer. The hyperparameter N decides how many words in the history from the current word should be taken into account for the next word prediction. In input layer, words are encoded as one hot encoding with vocabulary size V. The Matrix C is shared projection matrix with dimension N × D where D is embedding size. The hidden layer is densely connected to the projection layer which leads to the weights matrix of N×D×H from projection to hidden layer, where H is hidden layer size. After generating hidden vector, output layer has weights (H×V) followed by a softmax layer. Hence total weights involved in NNLM are (N×D+N×D×H+H×V). Term (H×V) can be reduced to H×log2(V) using hierarchical softmax [F. Morin] where vocabulary is represented as a binary tree. Most of the complexity comes from the term (N×D×H) when N×D > V. This is avoided in the word2vec model by not using hidden layer in the model. When NNLM model gets trained, the projection matrix is used as the lookup table for trained word vectors.
2.2 Recurrent Neural Net Language Model (RNNLM) [T. Mikolov et al.]
In this model, there is no need to specify N as in the case of NNLM model. RNN encodes past history of all the words in the hidden state. Hidden state S(T) gets updated with the current input X(T) and hidden vector at S(T-1).
Simple Elman Network is used as RNN model in RNNLM where input is simply concatenation of X(T) which is input token at T and S(T-1) which represents hidden/context vector at (T-1). Only recurrent weights in the time dimension and hidden to output layer weights are involved in this network causing overall complexity of the model as (H×H+H×V). Note, there is no N term in model complexity as compared to NNLM model. Term (H×V) can be further reduced to H×log2(V) using hierarchical softmax. In this model, the computational bottleneck term is (H×H).
As from both of the above models, it is evident that “non linear hidden layer” is the reason for the most of the overall complexity. This imposes limitation for not utilising all of the training data data due to the hardware restrictions. Hence Word2vec proposed two simpler models that can be trained with larger datasets without compromising quality of the word vectors.
3. Word2Vec Models
This section introduces models used for training word2vec.
- Continuous bag of words model (CBOW)
CBOW model is derived from NNLM model with the exception of no linear hidden layer. The objective function of CBOW model is to predict the middle word when given past N/2 history words and N/2 future words. The best result is obtained by using N=8. In the projection layer, word vectors of N context words are simply averaged. There is no relevance of the position of the word in determining the word vector of the middle word hence the name “Bag of Words”. The term Continuous represents the vector space D.
An averaged vector is passed to the output layer followed by hierarchical softmax to get distribution over V. CBOW is a simple log-linear model where logarithm of the output of the model can be represented as the linear combination of the weights of the model. Total weights involved in training CBOW model are N×D+D×log(2)V.
2. Continuous skip-gram model
This model reverses an objective of CBOW model. Given the current word, it predicts the nearby context words both in history and future. As the name suggests, model predicts the N-grams words except the current word as its the input to the model, hence the name skip-gram. The value of N is chosen as 10. As distant words are less related to the current word, they are sampled less compared to nearby words for generating output labels. When N=10, random number R is generated between 1 to 10 with sampling strategy mentioned above and R history and future words are used as correct labels for skip-gram model.
The total complexity of the model is N×D+N×D×log2(V). Notice, N also gets multiplied to D×log2(V) term as its not a single class classification problem compared to CBOW, rather N class classification problem. Hence overall complexity of skip gram model is greater than the CBOW model.
4. Results
This section discusses about the results obtained by word2vec, NNLM and RNNLM models.
Test set preparation for evaluating quality of the trained word vectors:-
Earlier methods showed few examples of similar words in the tabular form while word2vec model prepared a comprehensive test set which has five semantic relations and nine syntactic relations between words. Currency:Country, City:State, Man:Woman, Capital city:Country are some examples of the semantic relationship between words in test set. Antonyms, Superlative degree, present participle, past tense of word and word itself holds syntactic relation. The questions are prepared from the list of semantic and syntactic relations of the words in the test set. One such example — “What is the word that is similar to small in the same sense as biggest is similar to big?” There is a superlative syntactic relation between big and biggest, small and smallest. The answer to the above question is found from the vector algebraic X=Vector(“biggest”)- Vector(“big”)+Vector(“small”). The word vector which is nearest to X using cosine distance similarity is predicted as an answer. Predicted output is correct match only if it correctly matches to the output. Synonyms of the output is still considered as incorrect match in evaluation. Accuracy metric is used on the test set.
4.1. Accuracy v/s word vector dimension and training corpus size
As seen from Table 1, with increasing dimensionality of word vector and training corpus size, accuracy increases in both directions while there is diminishing gain with increase in embedding size as compared to training corpus size.
Training criteria:
- Data – Google News Corpus with 6B tokens. Vocabulary size limited to 1M based on the frequency.
- Number of epochs: 3
- Optimizer: Stochastic gradient descent
- Initial learning rate: 0.025 with linear decay.
4.2. Accuracy v/s Model Architecture
Here, training data and vector dimension is kept constant and different model architecture’s performance is compared.
Training criteria
- Data – LDC corpora with 320M words, 82K vocabulary
- Vector dimension : 640
RNNLM model works better for syntactic queries while perform poor on semantic queries. There is a big improvement in the semantic and syntactic performance of NNLM model compared RNNLM model as RNNLM model is more simpler and could not generalise better. CBOW works better than NNLM model, achieving best results on syntactic test set using much lesser training time. Skip-gram model achieves best results on the semantic set with small reduction in syntactic performance compared to CBOW.
4.3. Large Scale Parallel Training
Word2vec models have also used DistBelief distributed framework [Jeffrey Dean] for large scale parallel training of the models. Due to the lower complexity of word2vec model, models are trained on the huge corpus utilising DistBelief distributed training which speeds up the training procedure. NNLM, CBOW and Skip-gram model are trained on Google News corpus with 6B tokens with 100,1000 and 1000 word vector dimension respectively. Training time depends on the complexity of the model. Due to the fact that NNLM model has high complexity, 100 dimensional word vector is chosen for it compared to 1000 of CBOW and Skip-gram. Surprisingly word vectors of CBOW and skip-gram gets trained faster than NNLM model. Skip-gram achieves highest test accuracy of 65.6% within 2.5 days of training using mini-batch asynchronous gradient descent update and Adagrad optimizer usingDistBelief.
5. Examples of learned relationships
Relationship vector (“R”) between words “A” and “B” is obtained by subtracting word vector (“A”) from word vector (“B”). The word vector nearest to vector(“C”)+vector(“R”) holds the same relationship with C as between A and B.
Some interesting examples of the trained relationship between word vectors from skip-gram model is shown in Table 4. Person:Occupation relationship is followed between Einstein:scientist, Messi:midfielder and Picasso:painter.
6. Summary
Word2vec vectors can be trained with either CBOW or Skip-gram approach. Due to less complexity of models, they are trained on the huge corpora and with higher dimensional vector to get better continuous representation of the word vectors. There are many interesting applications of using word2vec models in NLP tasks. The vectors act as features of the words while building neural network models. Similarity between words, out of the list words problems can also be solved using word2vec.
7. Implementation of Word2vec model in Python.
- Gensim implementation of word2vec:-
8. Resources
[1] Original research paper: https://arxiv.org/pdf/1301.3781.pdf
[2] A Neural Probabilistic Language Model research paper : https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
[3] Recurrent Neural Network based Language Model research paper: https://www.isca-speech.org/archive/archive_papers/interspeech_2010/i10_1045.pdf
[4] Hierarchical version of softmax research paper: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.221.8829&rep=rep1&type=pdf#page=255
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/03/16/word2vec-research-paper-explained/


