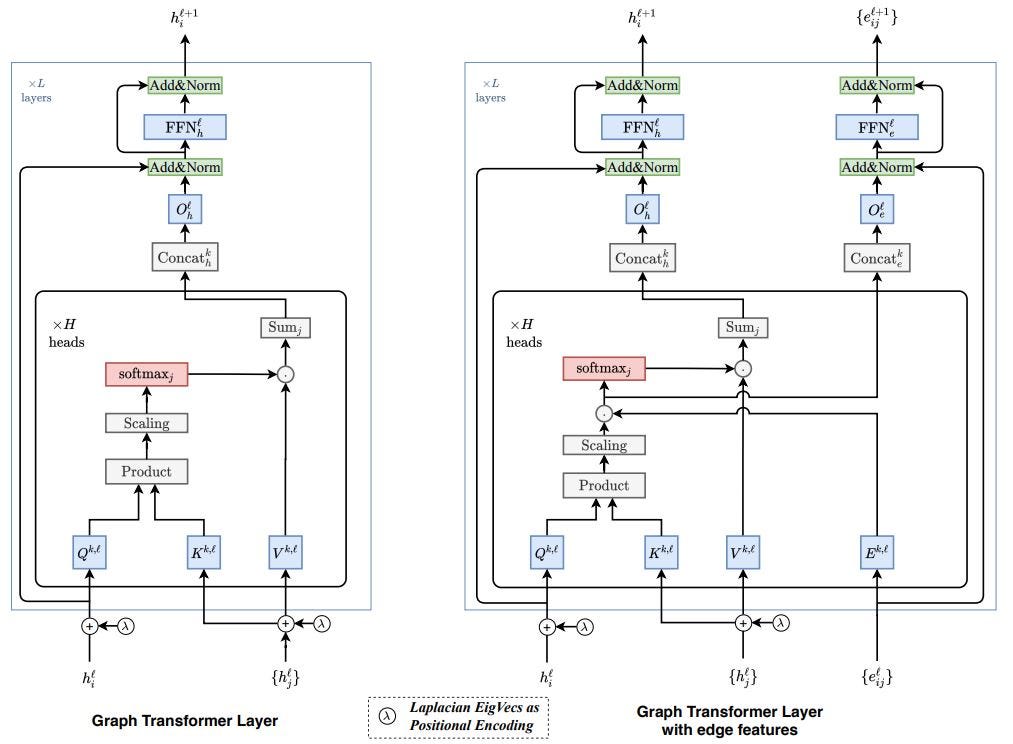
Graph Transformer: Generalization of Transformers to Graphs
Original Source Here
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I. (2017). Attention is all you need.
[2] Devlin, J., Chang, M.W., Lee, K. and Toutanova, K., (2018). Bert: Pre-training of deep bidirectional transformers for language understanding.
[3] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., (2018). Improving language understanding by generative pre-training.
[4] Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., (2020). Language models are few-shot learners.
[5] Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P. and Bengio, Y. (2018). Graph attention networks.
[6] Srinivasan, B. and Ribeiro, B., (2019). On the equivalence between positional node embeddings and structural graph representations.
[7] You, J., Ying, R. and Leskovec, J., (2019). Position-aware graph neural networks.
[8] Dwivedi, V. P., Joshi, C. K., Laurent, T., Bengio, Y., and Bresson, X. (2020). Benchmarking graph neural networks.
[9] Belkin, M. and Niyogi, P. (2003). Laplacian eigenmaps for dimensionality reduction and data representation.
[10] Ioffe, S. and Szegedy, C., (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift.
[11] Ba, J.L., Kiros, J.R. and Hinton, G.E., (2016). Layer normalization.
[12] Kipf, T. N., and Welling, M. (2016). Semi-supervised classification with graph convolutional networks.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/03/04/graph-transformer-generalization-of-transformers-to-graphs/


