SMOTE: Synthetic Data Augmentation for Tabular Data
Original Source Here
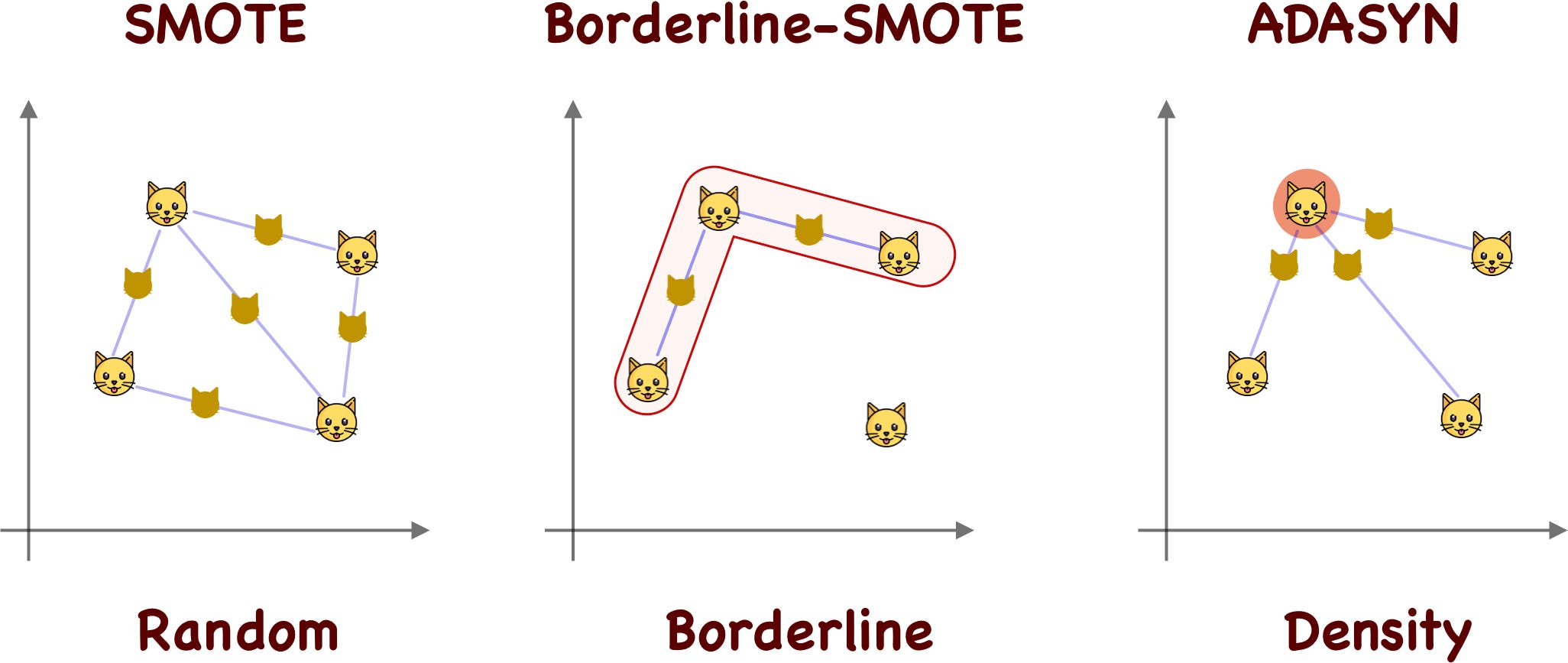
As can be seen in the previous image, the samples considered to generate synthetic samples are those that are in a low-density area. An alternative to ADASYN is K-Means-SMOTE which generates synthetic samples based on the density of each cluster found in the minority class.
SMOTE in practice
In this section, we will see the SMOTE [2] implementation and its variants (Borderline-SMOTE [3] and ADASYN [4]) using the python library imbalanced-learn [1]. In order to make a comparison of each of these techniques, an unbalanced dataset will be generated using the module make_classification of the scikit-learn framework. Later, visualizations corresponding to each algorithm will be shown as well as the evaluation of each model under the accuracy, precision, recall and f1-score metrics. Therefore, let’s start with the generation of the dataset.
Code snippet 1 generates a 2000 sample dataset with only 2 features and 2 classes where the majority class constitutes 95% of the dataset and the minority class only 5%. The visualization of the generated dataset is represented in Figure 5.
The implementation of SMOTE, Borderline-SMOTE and ADASYN is relatively simple thanks to the imbalanced-learn library. We only need to extend each of the required over-sampling algorithms and define some parameters for each algorithm. The implementation of each algorithm is shown in code snippet 2.
It is important to mention that for this example some fixed parameters were defined such as the case of the “k” nearest neighbors to be considered as well as the number of neighbors that determine when a sample is danger (for the case of Borderline-SMOTE ). These hyperparameters will depend on the size of the dataset, the class imbalance ratio, the number of samples in the minority class, etc.
Figures 6, 7 and 8 show the visualizations of the implementation of the SMOTE, Borderline-SMOTE and ADASYN algorithms respectively.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/03/01/smote-synthetic-data-augmentation-for-tabular-data/


