Role of Optimizer in Deep Learning to improve the Accuracy
Original Source Here
Role of Optimizer in Deep Learning to improve the Accuracy
The main objective of this post to make people understand the role and importance of optimizers in deep learning to improve accuracy. Before going into the actual subject, it is also essential to understand what is an optimizer? My previous post on Variants of Gradient Descent Optimizer in Deep Learning with Simple Analogy gives you a basic interpretation of optimizers with a simple example.
What is an Optimizer?
It is an algorithm that helps to change or update the parameters like weights, learning rate to mitigate the loss. Is it not simple?
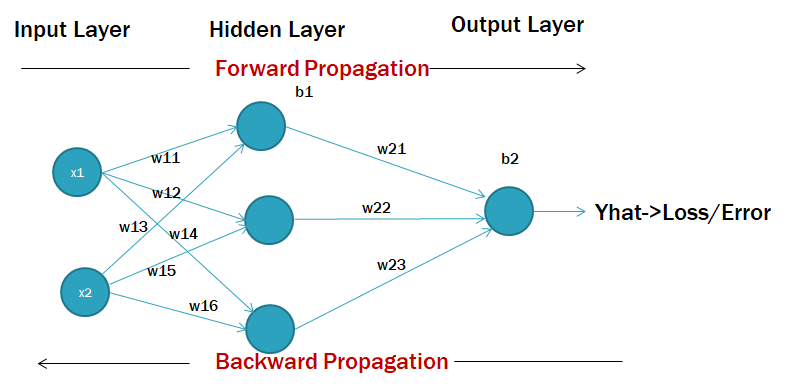
Well, look at figure 1 of the simple neural network structure.
The structure composes of input, hidden, and output layers. As of now, I am not going detailed explanation of each layer, rather I am going to highlight the role of optimizer with respect to “Yhat” (loss/error). Before that, we should understand what is forward and backward propagation. Remember that, 1 forward and backward propagation makes one epoch. What does it mean?
It means when we perform forward propagation to find the loss i.e. difference between actual values and predicted values. If the difference is large then it is time to reduce that loss. And how it is done?
It is done by updating the parameters. How do we update? Well, to do that, we need to go back and change the weights and learning rate such that the loss is minimized. This is known as back-propagation or backward propagation. While going back, we will be changing the values of weights and learning rate by finding their derivatives with respect to loss. It is highlighted with a red arrow for weights (w23, w16).
Hence, Derivatives helps to update the parameters to reach the global minima point in Gradient Descent, which indicates the loss is almost zero. What is the global minima point? well, you can go back to my post on https://manasanoolumortha.medium.com/variants-of-gradient-descent-optimizer-in-deep-learning-with-simple-analogy-6f2f59bd2e26 to know about it.
If you know what is Gradient Descent and the variants of it then it’s time to understand the convergence. Convergence means to meet at a single point. Does it make sense? 
Similarly to meet the closest point of minimum loss, we have to converge the parameters of optimizers. This can be better understood by the following example.
From figure 2, we can see that weights are converging towards the center point i.e. global minima. The red arrows indicate Gradient Descent (GD) which converges smoothly in a linear fashion. It is because gradient descent trains the whole records or data in one epoch. However, there is a drawback with this approach which is explained in https://manasanoolumortha.medium.com/variants-of-gradient-descent-optimizer-in-deep-learning-with-simple-analogy-6f2f59bd2e26.
Well, if we see the graph for SGD and Mini Batch GD, we can observe the zig-zag nature of convergence. It is because the SGD and Mini Batch GD works on iterations per epoch. It can be visualized in figure 3.
Let’s understand from a simple example. Suppose we have 10k records to train and in 1 epoch we have to iterate over these as shown in figure 4. While iterating, we could see the behavior of convergence from figure 3. It happens because, in GD, we are processing the whole dataset or records in 1 iteration, hence, the convergence is straight and smooth(red arrow). However, in real-time, the data will be in millions, in this case, GD will not work efficiently because of its memory size and computational power.
As we can from figure 4, in GD all the records are processed in 1 iteration, so the convergence will be smooth with a fixed learning rate. New term!! :O
What is the Learning rate?
Well!! the learning rate is a small value of a function that helps to map the best inputs to outputs from the examples in the training data. It is also a hyperparameter in a neural network to improve accuracy. Generally, its value ranges from 0.01 to 0.001. The arrows shown in the contour plot determine the learning rate i.e. steps to reach the center point (global minima).
Hence, the learning rate is an important parameter to consider while optimizing the training data for accuracy. Now, if we go to SGD, you can see that each record is processed per iteration. Assume if you have 10k records then how many iterations have to perform? Well, it is 10k*10k iterations :O
So, in the graph, the arrows go in zig-zag format because at each iteration it halts and goes to the next. It’s nothing but a Noise. Noise means we are not going smoothly as GD rather we are having halts in between to reach the center point. Even though SGD is faster than GD, still due to Noise, it demands a solution. Here comes, Mini Batch GD. To reduce the noise or to reduce the number of iterations, Mini Batch GD plays a Hero role :). It helps in reducing the noise by diving the records or data into batches or groups. Instead of iterating per record, it’s optimal to iterate over batches. It means, let’s take the same example of 10k records. Earlier in SGD, it took 10k iterations for the process in 1 epoch. Now, Mini Batch GD iterates over 1000 records per iterations i.e. for 10k records it just takes 10(10000/1000) iterations. Is it not optimal :O. That’s the reason for any type of optimizer, we consider Mini batch data for training.
However, even a hero can have problems :). Likewise, Mini Batch GD also has Noise issues as shown in figure 2. You can observe that even it is trained on the batch, still, it is iterated. So, it will also have Noise but lesser than SGD.
Now, the actual story starts with the entry of Optimizers to improve the Noise and train the data much efficiently and effectively. In my next post, I am gonna discuss the most prominent and popularly used optimizers. They are:
Momentum (Exponential Weighted Average)
Adaptive Gradient Descent (Adagrad)
AdaDelta and RMSProp
Adaptive Moment Estimation (Adam)
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/02/20/role-of-optimizer-in-deep-learning-to-improve-the-accuracy/


