Stochastic Gradient Descent (SGD)
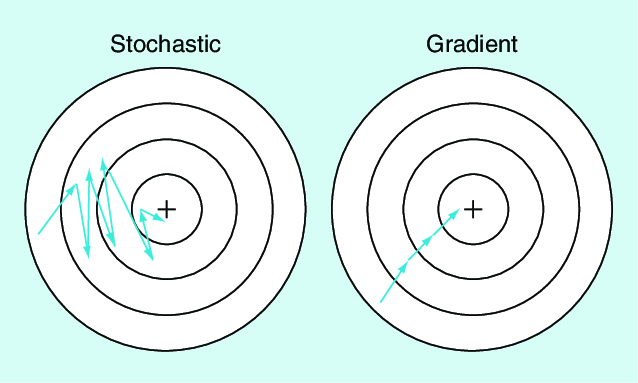
Original Source Here
Implementation
import the necessary packages
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
import argparsedef sigmoid_activation(x): # compute the sigmoid activation value for a given input
return 1.0 / (1 + np.exp(-x))def sigmoid_deriv(x):
# compute the derivative of the sigmoid function ASSUMING
# that the input `x` has already been passed through
# the sigmoid activation function
return x * (1 - x)def predict(X, W):
# take the dot product between our features and weight matrix
preds = sigmoid_activation(X.dot(W))
# apply a step function to threshold the outputs to binary
# class labels
preds[preds <= 0.5] = 0
preds[preds > 0] = 1
# return the predictions
return predsdef next_batch(X, y, batchSize):
# loop over our dataset `X` in mini-batches, yielding a tuple of
# the current batched data and labels
for i in np.arange(0, X.shape[0], batchSize):
yield (X[i:i + batchSize], y[i:i + batchSize])# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=float, default=100,
help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01,
help="learning rate")
ap.add_argument("-b", "--batch-size", type=int, default=32,
help="size of SGD mini-batches")
args = vars(ap.parse_args())# generate a 2-class classification problem with 1,000 data points,
# where each data point is a 2D feature vector
(X, y) = make_blobs(n_samples=1000, n_features=2, centers=2, cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))# insert a column of 1's as the last entry in the feature
# matrix -- this little trick allows us to treat the bias
# as a trainable parameter within the weight matrix
X = np.c_[X, np.ones((X.shape[0]))]
# partition the data into training and testing splits using 50% of
# the data for training and the remaining 50% for testing
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.5, random_state=42)# initialize our weight matrix and list of losses
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
losses = []# loop over the desired number of epochs
for epoch in np.arange(0, args["epochs"]):
# initialize the total loss for the epoch
epochLoss = []
# loop over our data in batches
for (batchX, batchY) in next_batch(trainX,
trainY, args["batch_size"]):
# take the dot product between our current batch of features
# and the weight matrix, then pass this value through our
# activation function
preds = sigmoid_activation(batchX.dot(W))
# now that we have our predictions, we need to determine th
# `error`, which is the difference between our predictions
# and the true values
error = preds - batchY
epochLoss.append(np.sum(error ** 2))
# the gradient descent update is the dot product between our
# (1) current batch and (2) the error of the sigmoid
# derivative of our predictions # update our loss history by taking the average loss
# across all
# batches
loss = np.average(epochLoss)
losses.append(loss)
# check to see if an update should be displayed
if epoch == 0 or (epoch + 1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(
epoch + 1), loss))# evaluate our mode
print("[INFO] evaluating...")
preds = predict(testX, W)
print(classification_report(testY, preds))# plot the (testing) classification data
plt.style.use("ggplot")
plt.figure()
plt.title("Data")
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY[:, 0], s=30)
# construct a figure that plots the loss over time
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()
Happy Learning!!!
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/01/31/stochastic-gradient-descent-sgd/


