Natural Language Processing: tokenization and numericalization
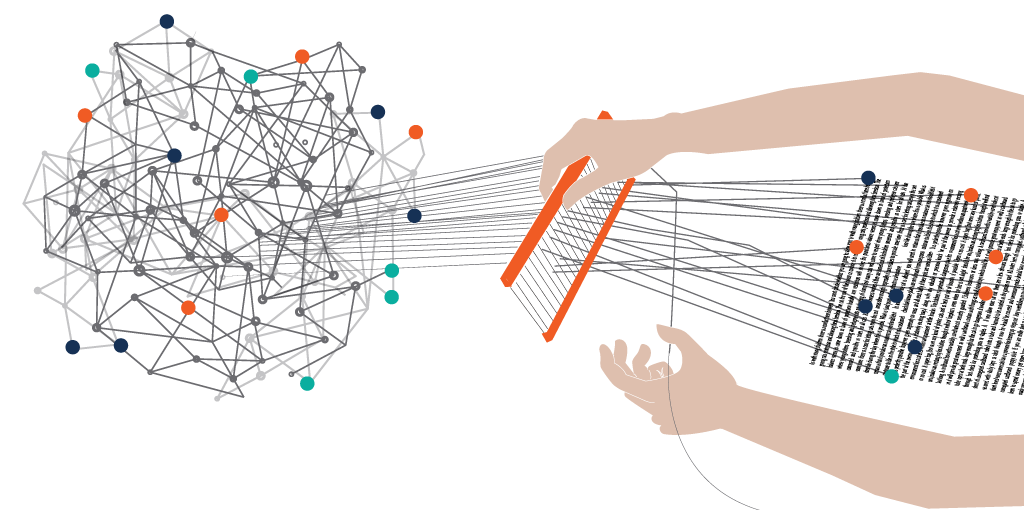
Original Source Here
Natural Language Processing: tokenization and numericalization
NLP nowadays is considered to be one of the most booming fields in Deep Learning, offering more and more possible applications, starting from detecting or generating articles and reviews heading into direction of medical applications like diagnosis recognition, not mentioning extensive business opportunities.
How does it work?
The basic initial step is converting texts using Tokenization method, which ‘breaks’ raw text in smaller pieces. Tokens can be words, singles characters or subwords (n-gram characters: a contiguous sequence of n items from a given sample of text or speech). The most common way of tokenization is based on space. Taking space as a delimiter for example, you will get from “Natural Language Processing” 3 tokens : “Natural”, “Language”, “Processing”.
Major techniques for tokenizing are:
- Split(): split method is used to break the given string in a sentence and return a list of strings by the specified separator.
- Spacy: Texts are split using rules that are specific for each language, so how the splitting is done for English would be different then for in German. These Prebuilt neural network models are available for English, German, Greek, Spanish, Portuguese, French, Italian, Dutch, Lithuanian and Norwegian, and there is also a multi-language NER model. Additional support for tokenization for more than 50 languages allows users to train custom models on their own datasets as well.
- Gensim: package for topic and vector space modeling, document similarity.
- Regular Expression: regex function is used to match or find strings using a sequence of patterns consisting of letters and numbers.
- NLTK (Natural Language Toolkit) library: breaks the given string and returns a list of strings by the white specified separator. NLTK is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
- Dictionary Based Tokenization: based on the tokens already existing in the dictionary
- Rule Based Tokenization: based on a set of rules are created for the specific problem
- Penn TreeBank Tokenization: Tree bank is a corpus, which gives the semantic and syntactic annotation of language
and many others. Which method to use will depend on your text (language, presence of white spaces or characters, special signs, type of genre (medical, scientific, etc.)) and tasks you need to achieve. Below is a good “pros and cons” comparison table for different libraries, which allows you in a more easy way to see, which method can be applicable in which case:
Numericalization
In order to turn tokens into numbers so that we can pass them into the neural network, we do numericalization, which can be achieved via creating a string-to-integer (i.e. stoi) and then use this to encode each of the tokenized sentences. In this way we are getting arrays, representing numericalized words and sentences which we can feed to the model.
You are ready to proceed to the next step: putting texts into batches for a Language Model!
Sources:
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/02/01/natural-language-processing-tokenization-and-numericalization/


