ทำนายประเภทของหนังสือจากหน้าปกด้วย Deep learning
Original Source Here
ทำนายประเภทของหนังสือจากหน้าปกด้วย Deep Learning
เคยสังเกตกันไหมว่าหน้าปกของหนังสือแต่ละประเภทจะมีลักษณะบางอย่างที่คล้าย ๆ กันอยู่ ยกตัวอย่างเช่น การจัดวางหน้า องค์ประกอบหรือการเลือกใช้โทนสี โดยบางครั้งเราก็สามารถรู้ได้ในทันทีที่เห็นหน้าปกของหนังสือว่าหนังสือเล่มนี้เป็นหนังสือประเภทไหน เป็นเพราะว่าเราเคยเห็นหนังสือที่มีลักษณะแบบนี้มาก่อน
ซึ่งโปรเจคนี้จะนำเอา Deep learning มาใช้ในการทำนายประเภทของหนังสือ โดยการทดลองให้คอมพิวเตอร์เรียนรู้แพทเทิร์นที่ซ่อนอยู่ในปกหนังสือแต่ละประเภท
Dataset
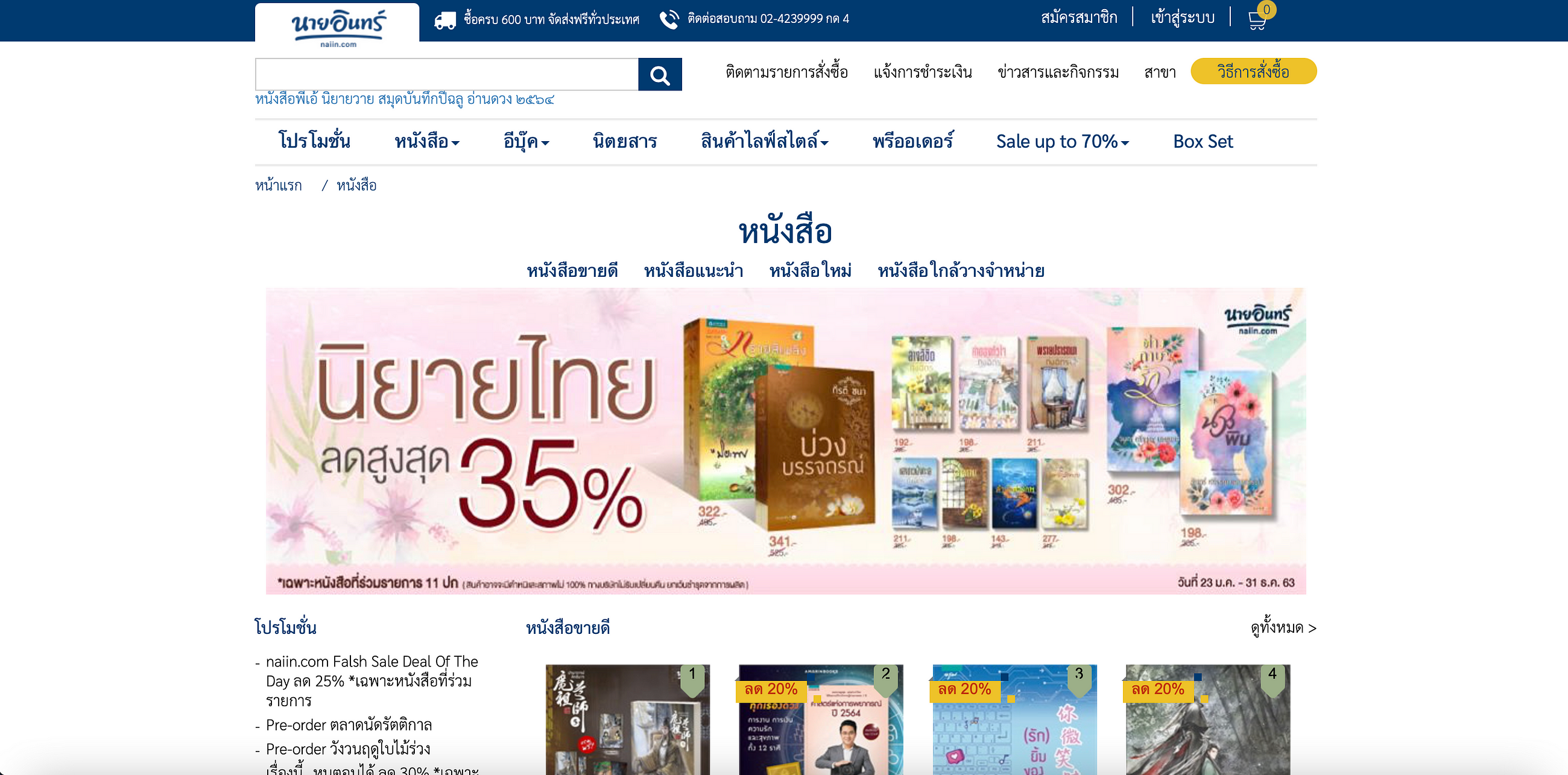
ชุดของข้อมูลที่จะนำมาใช้ในการ train model มาจากการทำ Web scraping รูปหน้าปกหนังสือจากเว็บไซต์ naiin.com ซึ่งเหตุผลในการเลือกใช้ข้อมูลจากเว็บไซต์นี้เนื่องจากเป็นร้านหนังสือที่มีข้อมูลของหนังสืออยู่เป็นจำนวนมากและการจัดหมวดหมู่ที่ไม่ซับซ้อน
เว็บไซต์ naiin.com ได้ทำการจัดหมวดของหนังสือเป็น 21 หมวด
Web scraping
ในการทำ Web scraping เราได้ใช้ library ชื่อ Requests ในการ download content ของเว็บไซต์มาในรูปแบบของภาษา HTML และใช้ library ชื่อ BeautifulSoup ในการค้นหา Tag ที่สนใจในหน้าเว็บไซต์นั้น ๆ เพื่อนำมาใช้ในการดาวโหลดน์ต่อไป
Problem
1.เมื่อพิจารณาข้อมูลปกหนังสือที่อยู่บนหน้าเว็บไซต์พบว่าหนังสือที่อยู่ในหน้าท้าย ๆ ไม่มีข้อมูลปกหนังสือ
2.ข้อมูลของหนังสือแต่ละหมวดมีจำนวนที่ไม่เท่ากัน บางหมวดมีจำนวนหนังสือไม่ถึง 1000 เล่ม
Solution
ในการเตรียมข้อมูลเพื่อนำมาใช้ในการ train ควรทำให้ข้อมูลในทุก ๆ class มีความสมดุลกันดังนั้นเราจึงทำการพิจารณาจำนวนข้อมูลของแต่ละหมวดเพื่อหาจำนวนที่เหมาะสม
หลังจากการ Clean ข้อมูลของหนังสือที่ไม่มีหน้าปกและพิจารณาจำนวนของข้อมูลที่เหลือแล้ว เราได้กำหนดให้จำนวนของข้อมูลที่ใช้ในการ train model ในแต่ละหมวดมีจำนวน 1900 รูป โดยจะทำการตัดหมวดที่มีจำนวนข้อมูลไม่ถึงจำนวนที่กำหนดออกและนำข้อมูลของหมวดที่มีจำนวนของข้อมูลเกินกว่าที่กำหนดเก็บไว้ใช้ในการทดสอบโมเดลต่อไป
จำนวนที่กำหนดนี้อิงจากจำนวนข้อมูลของหนังสือหมวดคอมพิวเตอร์ เนื่องจากเมื่อพิจารณาหนังสือหมวดอื่น ๆ ที่มีจำนวนข้อมูลน้อยกว่าหนังสือหมวดคอมพิวเตอร์พบว่ามีผลต่างของจำนวนที่มากเกินไป ซึ่งหากต้องการเก็บข้อมูลหมวดนั้น ๆ ไว้จำเป็นต้องทิ้งข้อมูลเป็นจำนวนมาก
โดยหลังจากทำการตัดข้อมูลบางหมวดออกจะทำให้เหลือข้อมูลทั้งหมด 14 หมวดดังต่อไปนี้
Model
การทำงานในส่วนนี้จะใช้ Keras ซึ่งเป็น API บน Tensorflow ในการ train model
Import data to dataset
ในส่วนของการ import รูปเพื่อมาใช้ในการ train model นั้น เราใช้ function ของ Keras ชื่อ image_dataset_from_directory ซึ่งจะช่วยนำรูปที่อยู่ใน subfolder ของ path ที่กำหนดมาจัดเก็บเป็น class ซึ่งในโปรเจคนี้ class คือหมวดหมู่ของหนังสือ
path = '/Users/tt1/Desktop/Balancedtest/'
img_height = 128
img_width = 128
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
path,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
path,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
num_classes = 14
Train-test split
เนื่องจากข้อมูลที่มีจำนวนไม่มากจึงจำเป็นต้องมีการใช้อัตราส่วนของ test set ในสัดส่วนที่มากพอสมควร เพื่อให้โมเดลสามารถทำงานได้ดีกับข้อมูลที่ไม่เคยเห็นมาก่อน จึงแบ่งสัดส่วน train:test เป็น 80:20
Image size
จากการ Explore ข้อมูลพบว่ารูปภาพส่วนใหญ่มีความกว้างอยู่ในช่วง 120–130 pixels ซึ่งในการนำรูปภาพมาใช้ในการ train model จำเป็นต้องทำให้รูปภาพทั้งหมดมีขนาดที่เท่ากัน ดังนั้นเราจึงทำการ resize ภาพทั้งหมดให้มีขนาด 128×128 pixels
Model architecture
ในการสร้างโมเดลพยากรณ์ เราได้นำ Convolution neural network มาใช้ในการสร้างโมเดล โดยเลือกใช้ ResNet50 architecture มาใช้ในการ Extract feature จากรูปภาพปกหนังสือ เนื่องจากขนาดที่ไม่ใหญ่มากและใช้งานง่ายเนื่องจากเป็น Function ที่อยู่ใน Keras อยู่แล้ว โดยกำหนดให้ input shape = (128,128,3) มาจากขนาดของรูปที่ 128×128 pixels โดยจะมี 3 layers ตาม RGB channel เนื่องจากเป็นภาพสี
resnet = tf.keras.applications.ResNet50(
include_top=False,
weights="imagenet",
input_shape=(128,128,3)
)
เราได้ทำการตัดส่วน top layer ของ ResNet50 architecture ออกและใส่ Layer ที่มี output layer เท่ากับ จำนวน class ที่มีเข้าไปแทน
x = tf.keras.Sequential([
model_res,
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.3),
layers.Dense(256, activation='relu'),
layers.Dropout(0.4),
layers.Dense(256, activation='relu'),
layers.Dense(num_classes)
])
Metric
โปรเจคนี้จะใช้ Top_k_categorical_accuracy เป็น metric ในการวัดความแม่นยำในการทำนายของโมเดล
หลักการวัดความแม่นยำของ Top_k_categorical_accuracy คือ หากโมเดลทำนายความน่าจะเป็นของ class ที่ถูกต้องให้อยู่ใน k อันดับแรกได้จะให้ค่าเป็น 1 ถ้าไม่ได้จะให้ค่าเป็น 0 โดยเราจะกำหนดให้ค่า k = 3 ซึ่งหมายถึงถ้าความน่าจะเป็นของ class ที่ถูกต้องอยู่ใน Top 3 โมเดลจะได้คะแนนไป 1 แต้ม
Example
จากรูปตัวอย่างด้านบน รูปที่หนึ่งคือรูปจากหมวดหนังสือท่องเที่ยวซึ่งถึงแม้ว่า model จะไม่ได้ทำนายว่าหนังสือเล่มนี้มีความน่าจะเป็นหนังสือท่องเที่ยวมากที่สุด แต่ว่าหมวดหนังสือท่องเที่ยวก็อยู่ใน top 3 ดังนั้น metric จึงให้ 1 คะแนน
ในขณะที่รูปที่สองซึ่งเป็นหนังสือการ์ตูนแต่ความน่าจะเป็นของหมวดการ์ตูนไม่ได้อยู่ใน top 3 ดังนั้น metric จึงให้ 0 คะแนน
Fit model
หลังจากทำการกำหนด metric ที่ใช้ในการวัดความถูกต้องของการพยากรณ์แล้วต่อไปก็คือการ fit model กับ dataset ที่เราเตรียมไว้ โดยให้ epochs เป็น 30 เพื่อไม่ให้ใช้เวลานานจนเกินไป เนื่องจากข้อจำกัดทางด้านทรัพยากรและเวลา
x.fit(
train_ds,
validation_data=val_ds,
epochs= 30 ,
)
จากการ train model พบว่าความแม่นยำของข้อมูลอยู่ที่ 0.6618 จากการทดสอบด้วย function evaluate
Analyze
จากการนำข้อมูลที่เหลือมาทดสอบการจัดหมวดหมู่ของโมเดลพบว่าปัญหาส่วนหนึ่งที่ทำให้โมเดลมีความไม่แม่นยำมาจากการจัดหมวดหมู่ของเว็บไซต์ เนื่องจากมีบางหมวดหมู่นั้นไม่เป็นอิสระต่อกัน หมายความว่าถ้าอิงตามหลักความจริงจะมีหนังสือบางเล่มที่สามารถถูกจัดให้อยู่ในหมวดหมู่ได้มากกว่าหนึ่งหมวด
ตัวอย่างในภาพด้านบนคือหนังสือหมวดหนังสือเด็กที่ถูกโมเดลทำนายให้อยู่ในหมวดเตรียมสอบ ซึ่งหากพิจารณาแล้วหนังสือเหล่านั้นสามารถถูกจัดให้อยู่ในหมวดเตรียมสอบได้ แปลว่าจริง ๆ แล้วโมเดลก็มีความสามารถในการแยกรูปแบบของหนังสือเตรียมสอบที่ดีระดับหนึ่ง แต่ผิดที่การแบ่งหมวดหมู่
ปัญหาของการแบ่งหมวดหมู่นี้คือ หมวดหนึ่งเป็นหมวดที่แบ่งจากช่วงวัยส่วนอีกหมวดหนึ่งเป็นหมวดที่แบ่งจากวัตถุประสงค์ทำให้มีโอกาสที่จะเกิดส่วนที่ Intersect กันได้
Summary
การพัฒนาโมเดลนี้ให้มีความแม่นยำในการทำนายที่สูงขึ้นควรเริ่มจากการปรับปรุงการจัดหมวดหมู่ของหนังสือโดยกำหนดหมวดหมู่ (Class) ให้เป็นอิสระต่อกัน
ถ้ามีข้อผิดพลาดตรงไหนรบกวนช่วยแนะนำด้วยนะครับ
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2020/11/29/%e0%b8%97%e0%b8%b3%e0%b8%99%e0%b8%b2%e0%b8%a2%e0%b8%9b%e0%b8%a3%e0%b8%b0%e0%b9%80%e0%b8%a0%e0%b8%97%e0%b8%82%e0%b8%ad%e0%b8%87%e0%b8%ab%e0%b8%99%e0%b8%b1%e0%b8%87%e0%b8%aa%e0%b8%b7%e0%b8%ad%e0%b8%88/


