How to improve your linear regression with basis functions and regularization
Original Source Here
How to improve your linear regression with basis functions and regularization
Introduction to basis functions and regularization with theory and Python implementation
Contents
This post is a part of a series of posts that I will be making. You can read a more detailed version of this post on my personal blog by clicking here. Underneath you can see an overview of the series.
1. Introduction to machine learning
2. Regression
Basis functions
In the previous post we discussed the linear regression model
We say that a model is linear if it’s linear in the parameters not in the input variables. However, (1) is linear in both the parameters and the input variables, which limits it from adapting to nonlinear relationships. We can augment the model by replacing the input variables with nonlinear basis functions of the input variables
where
By using nonlinear basis functions it is possible for h to adapt to nonlinear relationships of x, which we will see shortly — we call these models linear basis function models.
We already looked at one example of basis functions in the first post of the series, where we augmented the simple linear regression model with basis functions of powers of x, i.e.,
Another common basis function is the Gaussian
Following the same derivation as in the previous post, we find the maximum likelihood solutions for w and α to be
where
The image below shows a linear basis function model with M-1 Gaussian basis functions. We can see that increasing the number of basis functions makes a better model, until we start overfitting.
Implementation
Using the same dataset as in the previous posts, we get the implementation below.
Regularization
We briefly ran into the concept of regularization in the post on Bayesian inference, which we described as a technique of preventing overfitting. If we look back at the objective function we defined in the previous post (augmented with basis functions) we can introduce a regularization term
where q>0 denotes the type of regularization, and λ controls the extent of regularization.
The most common values of q are 1 and 2, which are called L1 regularization and L2 regularization respectively. We call it lasso regression when we use L1 regularization, and ridge regression when we use L2 regularization.
The objective function of ridge regression
is especially convenient as it is a quadratic function of w and therefore has a unique global minimum. The solution to which is
where α stays the same as without regularization, since the regularization term has no influence on it.
When we introduce regularization, the process of model selection goes from finding the appropriate number of basis functions to finding the appropriate value for the regularization parameter λ.
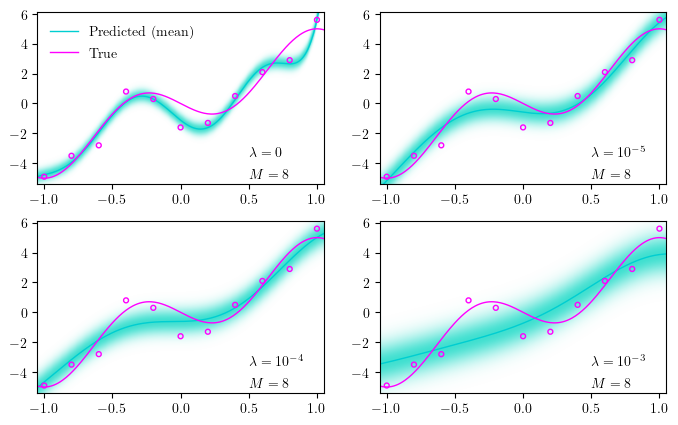
The image below shows a linear basis function model with varying values for λ, while keeping the number of basis functions constant M=8. We can see that even though we overfit to begin with, we can adjust the regularization parameter λ to prevent it — in fact, we start underfitting when the regularization is too much. Another interesting thing to see is that our uncertainty increases along with the regularization.
Implementation
Summary
- What makes a model linear is that it’s linear in the parameters not the inputs.
- We can augment linear regression with basis functions yielding linear basis function models.
- Polynomial regression is a linear basis function model.
- Regularization is a technique of preventing overfitting.
- There are different kinds of regularization in linear regression such as L1 and L2 regularization.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/03/25/how-to-improve-your-linear-regression-with-basis-functions-and-regularization/


