OpenVINO™ Model Server Boosts AI Inference Operations
Original Source Here
OpenVINO™ Model Server Boosts AI Inference Operations
When executing inference operations, AI practitioners need an efficient way to integrate components that delivers great performance at scale.
This post was originally published on Intel.com.
Author: Dariusz Trawinski
When executing inference operations, AI practitioners need an efficient way to integrate components that delivers great performance at scale while providing a simple interface between application and execution engine.
Thus far, TensorFlow* Serving has been the serving system of choice for several reasons:
- Efficient serialization and deserialization
- Fast gRPC interface
- Popularity of the TensorFlow framework
- Simple API definition
- Version management
There are, however, a few challenges to the successful adoption of TensorFlow Serving:
For successful adoption, an inference platform should include acceptable latency even for demanding workloads, easy integration between training and deployment systems, scalability and a standard client interface. A new model server inference platform developed by Intel, the OpenVINO™ Model Server, offers the same interface as TensorFlow Serving gRPC API but employs inference engine libraries from the Intel® Distribution of OpenVINO™ toolkit. Based on convolutional neural networks (CNN), this toolkit extends workloads across Intel® hardware (including accelerators) and maximizes performance across computer vision accelerators — CPUs, integrated GPUs, Intel Movidius VPUs, and Intel FPGAs
Performance Results
Intel’s Poland-based AI inference platform team compared results captured from a gRPC client run against a Docker container using a TensorFlow* Serving image from Docker Hub (tensorflow/serving:1.10.1) and a Docker image built using an OpenVINO Model Server image with Intel Distribution for OpenVINO toolkit version 2018.3. We applied standard models from TensorFlow-Slim image classification models library, specifically resnet_v1_50, resnet_v2_50, resnet_v1_152 and resnet_v2_152.
Using identical client application code and hardware configuration in the Docker containers, OpenVINO Model Server delivered up to 5x the performance of TensorFlow Serving, depending on batch size. The improved performance of the OpenVINO Model Server means that the inference interface can be easily accessible over a network, opening new opportunities for supported applications and reducing the cost, latency and power consumption.
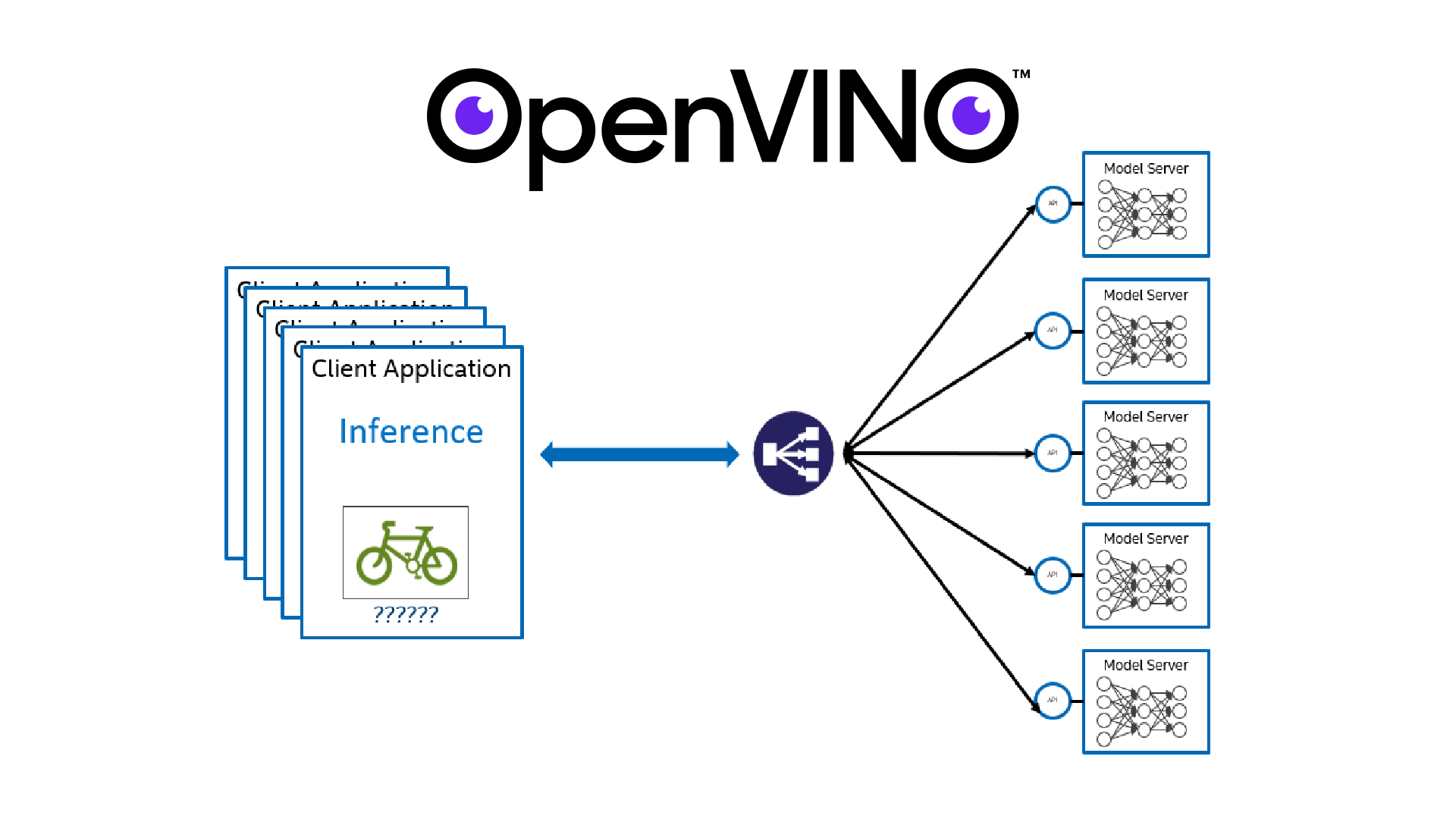
How OpenVINO™ Model Server Works
Models trained in TensorFlow, MxNet*, Caffe*, Kaldi*, or in ONNX format are optimized using the Model Optimizer included in the OpenVINO toolkit. This process is done just once. The output of the model optimizer is two files with .xml and .bin extensions. The XML represents the optimized graph, and the bin file contains the weights. These files are loaded into the Inference Engine, which provides a lightweight API for integration into the actual runtime application.OpenVINO Model Server allows these models to be served through the same gRPC interface as TensorFlow Serving.
An automated pipeline can be easily implemented, which first trains the models in the TensorFlow framework, then exports the results in a protocol buffer file and later converts them to Intermediate Representation format. As long the model includes layer types supported by OpenVINO, there are no extra steps needed. However, for a few non-supported layers there is still a way to complete the transformation by installing appropriate extensions for the missing operations. Refer to the Model Optimizer documentation for more details.
The same conversion can be completed for Caffe and MXNet models (and the recent OpenVINO release 2018.3 also supports Kaldi and ONNX models.) As a result, the OpenVINO Model Server can become the inference execution component for all these deep learning frameworks.
OpenVINO Model Server
The OpenVINO Model Server architecture stack is shown in Figure 5. It is implemented as a Python* service with gRPC libraries exposing the API from the TensorFlow Serving API. These are used as identical proto files, which make the API implementation fully compatible for the same clients. Therefore, no code changes are needed on the client side to connect to both serving components.
Key differences include inference execution implementation which relies on the Inference Engine API. With an optimized model format, and using Intel-optimized libraries for inference execution on CPUs, FPGAs, and VPUs, you can take advantage of significantly better performance.
OpenVINO Model Server is well suited for Docker containers. This allows OpenVINO Model Server to be employed in edge, data center and cloud architectures such as AWS Sagemaker. The image building process is very straightforward and much faster comparing to TensorFlow Serving*. Implementation of this image building process simplifies the hosting and inference service on any operating system and platform. By exposing the service via a gRPC interface the execution engine becomes available for applications written in most languages (C#, C++, Java, Golang, JavaScript, Python etc), which makes the integration seamless for developers.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/02/19/openvino-model-server-boosts-ai-inference-operations/


