Deep Learning Interview Questions
Original Source Here
What are the steps of deep learning?
1. create a function (neural network)
2. evaluate the goodness of the function
3. pick the best function as the final question answer machine
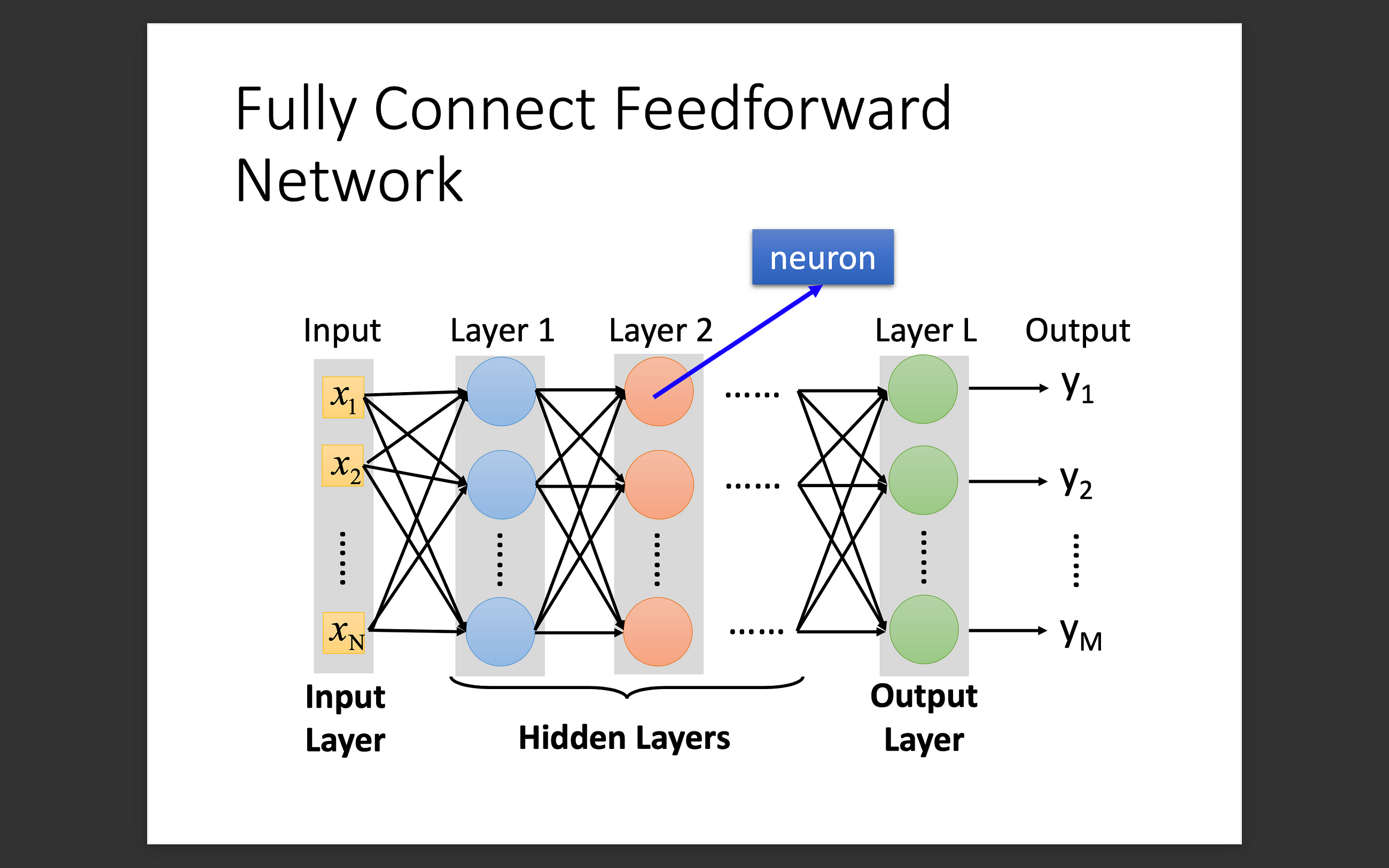
What is a neural network?
Neural network simulates the ways human learn but is much simpler. It can be imagined as a function. When you feed it input, you are supposed to get an output. It commonly consists of an input layer, hidden layer(s), and an output layer.
Why is it necessary to introduce non-linearities in the neural network?
If there are all linear functions, they actually compose a new linear function, which gives a linear model. A linear model has a much smaller number of parameters and is therefore limited in its complexity.
What is the difference between single-layer perceptron and multi-layer perceptron?
The main difference between them is the existence of hidden layers. Multi-layer perceptron can classify nonlinear data and withstand great numbers of parameters. (Except for the input layer, each node in the other layers uses a nonlinear activation function.)
Which one is better, shallow networks or deep networks?
Both shallow and deep networks are good enough and capable of approximating any function. But for the same level of accuracy, deeper networks can be much more efficient in terms of computation and number of parameters. Deeper networks can create deep representations. At every layer, the network learns a new, more abstract feartures of the input.
What is a activation function?
At the most basic level, an activation function decides whether a neuron should be activated or not. It accepts the weighted sum of the inputs and bias as input to any activation function. Sigmoid, ReLU, Maxout, Tanh, and Softmax are examples of activation functions.
For Sigmoid, the function transforms the values to the range [0, 1], but it is hard to compute. Besides, we might have a large input difference but lead to a small output gap, which causes gradient vanishing problems.
For ReLU, it simulates the biological neurons and is much faster to compute. The most important is ReLU solves the vanishing gradient problem.
For Maxout, instead of replacing the negative values to 0, we retain the maximum values among neurons in the same layer. In other words, we can say that ReLU is a special case of Maxout, which contains an always 0 neuron.
What is gradient descent, and what is the difference between batch gradient descent and stochastic gradient descent?
We would like to minimize the errors; therefore we move toward the opposite direction of the gradient of losses.
We consider the whole batch for normal gradient descent, which costs much time, but it is more stable.
For stochastic gradient descent, on the contrary, we consider only one example, making the process much faster.
What is the adaptive learning rate?
With intuition, we know that we would need a larger learning rate at the begin, and reduced as the steps go through. It determines how much we are moving to the direction computing by the gradient. Adagrad, RMSprop, and Adam are examples of adaptive learning rates.
For Adagrad, we divide the learning rate of each parameter by the root mean square of its previous derivatives, leading to smaller step when having moved a long distance.
For RMSprop, we divide the root mean square of the decayed previous derivatives instead of the average.
As for Adam, we combine the concepts of momentum and RMSprop. In this case, the movement is not just based on gradient, but also the previous movement, and can perhaps conquer the situation of local minima or saddle point.
What is loss function?
The loss function is used as a measure of accuracy to see if a neural network has learned accurately from the training data or not. In Deep Learning, a good performing network will have a low loss function at all times when training.
For regression tasks, the most commonly used method is mean square error. It computes the distance between the actual value and the predicted value so that we would gradually move toward the correct value by gradient descent algorithm.
For classification problems, we usually use cross entropy loss. Instead of measure the difference between specific values, we consider the distributions among different classes.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/03/01/deep-learning-interview-questions/


