[Paper Review] Gradient Descent Algorithms
Original Source Here
[Paper Review] Gradient Descent Algorithms
휴먼스케이프 Software engineer Covy입니다.
이번 포스트에서는 Machine Learning에 사용되는 다양한 optimizer가 배경으로 하는 gradient descent algorithms에 대해서 정리한 논문에 대해서 리뷰하려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“An overview of gradient descent optimization algorithms”
논문의 목적은 독자들에게 다양한 Gradient Descent Algorithm에 대한 직관을 가질 수 있게 하는 것입니다. 논문에 대한 내용을 직접 보시고 싶으신 분은 이곳을 참고하시면 좋습니다.
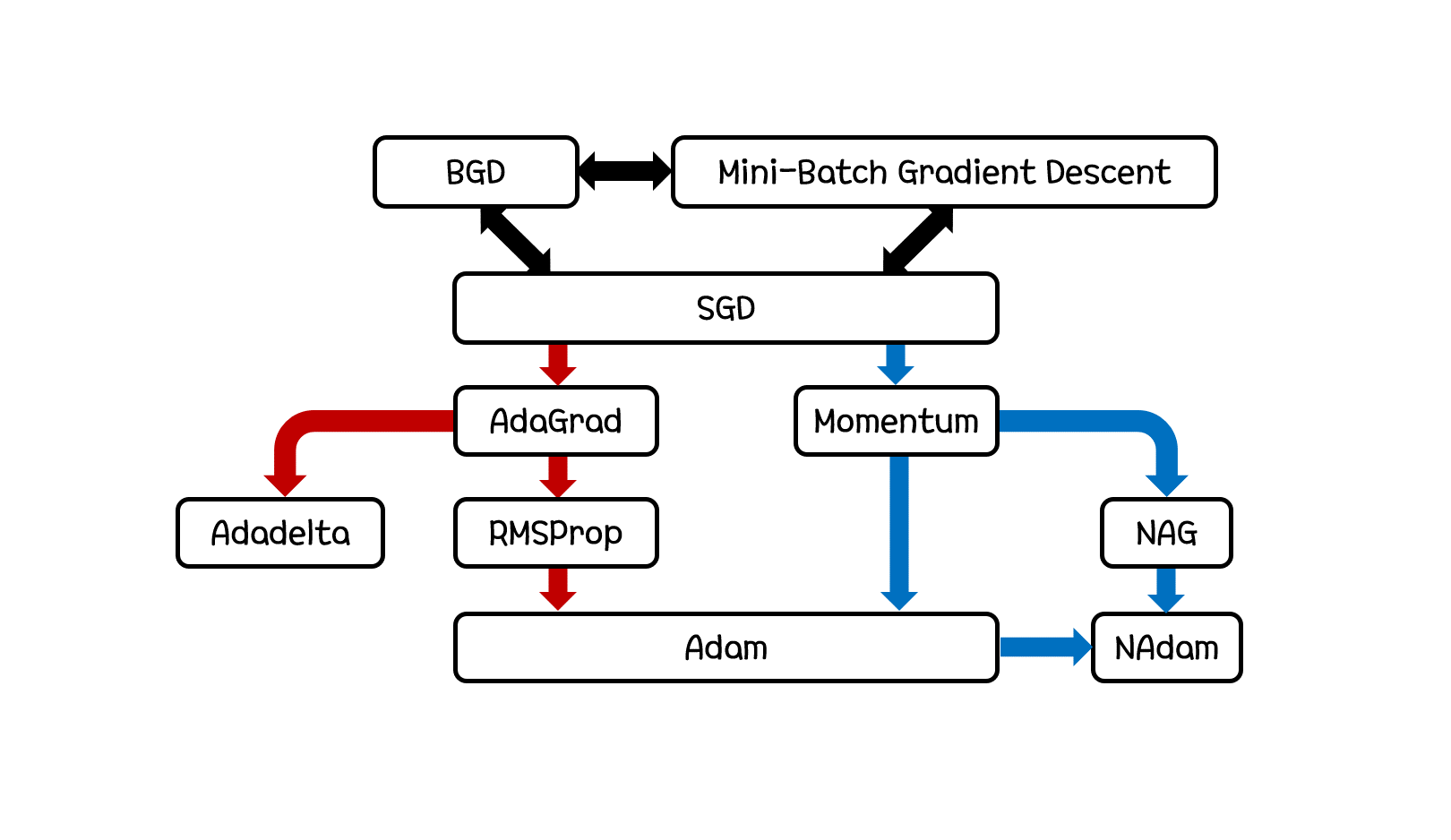
각각의 Gradient Descent Algorithm을 설명하기 전에 위 그림의 관계로 각각의 알고리즘이 탄생하게 되었다 정도를 가볍게 보고 넘어가시면 좋을 것 같습니다. 여기서 검은색 화살표의 경우 DataSet Size에 관련한 변화이며 붉은색 화살표의 경우 Step Size에 관련한 변화이고 푸른색 화살표의 경우 Step Direction에 관련한 변화로 보시면 됩니다.
자세한 설명을 지금부터 시작하겠습니다.
BGD (Batch Gradient Descent)
Batch Gradient Descent는 저희가 가장 기본적으로 알고 있는 Gradient Descent 입니다. 특정 step에서 특정 parameter theta가 본인에 대한 objective function J의 방향 미분성분만큼 변화하는 형태를 Gradient Descent라고 표현한다는 것을 저희는 너무도 잘 알고 있습니다. 이 때 objective function J가 전체 데이터셋에 대한 cost function의 합으로 이루어져 있는 경우를 Batch Gradient Descent 라고 부릅니다. 이 algorithm에서 짚고 넘어갈 점이 있다면 전체 데이터셋에 대한 objective function을 사용한다는 점입니다.
전체 데이터셋…?? Batch…??
다만, “Batch”라는 용어 때문에 저 또한 그랬고, 많은 분들이 처음에 혼동을 겪고는 합니다. 흔히 Batch는 학습 용어로 전체 dataset을 나눈 데이터 셋의 한 단위를 생각하기 쉽기 때문입니다. 하지만, Batch 자체는 전체 데이터 셋을 의미하며, 실제로 저희가 Batch로 많이 생각하는 것은 mini-batch로 보시는 것이 맞습니다.
SGD (Stochastic Gradient Descent)
BGD는 Machine Learning의 근본 algorithm이 되기에는 충분했습니다. 하지만, parameter를 한 번 update하기 위해서는 전체 데이터셋을 돌아 objective function을 계산해야 했고 학습 속도가 느리다는 단점이 있었습니다.
이를 개선하기 위해 등장한 것이 Stochastic Gradient Descent입니다.
BGD와의 차이점은 objective function J의 형태입니다. BGD가 전체 데이터셋에 대한 cost function의 합으로 이루어져 있었다면 SGD는 하나의 데이터로만 이루어져 있습니다. 그렇기 때문에 하나의 업데이트를 위한 계산과정이 오래 걸리지 않고 빠르게 진행될 수 있습니다.
부가적으로, SGD에서는 하나의 데이터를 사용해 계산하기 때문에 parameter의 fluctuation이 큰 편이며 이 때문에 기존 BGD에서 자주 발생하는 local minimum에 빠져서 나오지 못하는 현상이 SGD에서는 잘 나타나지 않는다는 것도 장점이 될 수 있습니다.
Mini-Batch Gradient Descent
SGD는 기존 BGD의 느린 학습속도를 해결해주기에는 적합한 algorithm이었으나, update마다의 큰 fluctuation이 algorithm의 convergence를 방해하는 경우가 나타난다는 단점이 있었습니다.
저희가 많이 겪는 레퍼토리이지만, 대부분의 경우에서 어떤 설계의 양극단이 가지는 큰 단점들을 적절히 보완하기 위해서 반씩 가져다가 섞는 것이 좋은 효율을 보이곤 합니다.
Mini-Batch Gradient Descent가 그 예시 중 하나라고 보시면 됩니다. 전체도, 하나도 아닌 적당한 크기의 데이터셋을 사용합니다.
위의 수식은 objective function J의 정의를 위해 n개의 데이터셋을 사용한 경우입니다. 전체를 다 이용하지 않아서 BGD보다 상대적으로 빠르고, 어느정도의 집단을 만들어 사용하기 때문에 SGD보다 수렴성이 좋습니다. 결과적으로, 이러한 시도를 통해서 빠르면서도 잘 수렴되는 gradient descent algorithm을 만들어냅니다.
Momentum
지금부터는 살짝 결이 다른 이야기가 들어갑니다. 앞서 설명드린 세 가지의 algorithm들은 objective function J가 정의되는 데이터셋의 범위에 한정된 이야기였습니다.
기존 SGD의 문제점 중 하나로 fluctuation이 크다는 것을 언급했던 적이 있습니다. 앞서는 수렴 자체를 방해할 수 있다고만 언급드렸는데, 추가적으로 local minima에 가까울 수록 경사가 급한 gradient descent를 산출해낼 가능성이 크며 수렴 속도도 느리게 하는 문제점이 있습니다.
이렇게 local minima에서 급하게 변하는 gradient를 제어해주기 위해 등장한 개념이 Momentum입니다. 단어에서 유추하신 분도 있겠지만 gradient에 관성의 성질을 더해주는 algorithm입니다. 그리고 그 방법으로 현재의 gradient를 산출하기 위해 과거의 gradient를 참고하여 반영하게 됩니다.
제가 동쪽으로 100m/s 의 속력으로 달리고 있는데 갑자기 다음 명령으로 서쪽으로 100m/s 로 달리려고 하면 바로 바꾸기는 쉽지 않습니다.
이러한 점을 반영하여 제가 동쪽으로 100m/s로 달리고 있었다는 사실을 다음 명령을 산출할 때 반영하여 서쪽으로 20m/s 정도로만 달리라는 것으로 완화한다고 생각하시면 됩니다.
물론… 과거의 gradient가 현재의 gradient보다 영향을 끼치는 정도가 커지면 안되겠죠??
이 때문에 momentum term인 gamma<1를 설정하여 반영합니다. 이렇게 설정하게 되면 더 먼 과거에 있었던 gradient가 현재 gradient에 미치는 영향은 적어지게 됩니다. 이런 형태로 이전 학습의 방향성을 어느정도 유지하여 학습의 속도를 빠르게 할 수 있었습니다.
Nesterov Accelerated Gradient (NAG)
Momentum에서 빠른 학습을 위해 이전 gradient의 방향성을 유지한다는 아이디어를 제시했었습니다.
그런데, 과거의 gradient의 방향성을 알고 반영하는 것 뿐만이 아니라 자신이 현재 예상한 자신의 gradient를 이용해 이동되었을 때의 위치에서의 gradient도 알 수 있다면, 더욱 빠른 학습이 가능하지 않을까라는 아이디어가 나왔습니다.
제가 동쪽으로 100m/s 의 속력으로 달리고 있는데 갑자기 다음 명령으로 서쪽으로 100m/s 로 달리려고 하면 바로 바꾸기는 쉽지 않습니다.
이러한 점을 반영하여 제가 동쪽으로 100m/s로 달리고 있었다는 사실을 다음 명령을 산출할 때 반영하여 서쪽으로 20m/s 정도로만 달리라는 것으로 완화할 생각입니다.
이렇게 완화하여 달릴 것을 가정하고 이렇게 일정 시간 달렸을 때 있게 될 제 위치에서 발견할 명령이 북쪽으로 15m/s로 달리는 것이라는 것을 저는 예측할 수 있습니다.
이러한 예측을 현재 제 판단에 어느정도 반영하여 최종적으로 북서쪽으로 25m/s 정도로 달리는 것으로 제 명령을 수행하는 것으로 변경한다고 생각하시면 됩니다.
Momentum과의 차이점은 objective function J에서 현재의 paramter theta가 아닌, 과거의 gradient와 momentum term gamma로만 계산한 변경될 parameter를 사용하여 계산을 한다는 점입니다.
식에서 볼 수 있듯이 현재의 gradient는 산출하기 전이기 때문에 과거의 gradient를 사용했습니다. 미래의 parameter를 미리 예측하고 그 objective function을 계산한 후 theta로의 방향 미분을 최종적으로 계산할 수 있습니다. 이를 통해 미래의 gradient를 미리 예측할 수 있고, 미래 학습의 방향성을 어느정도 감안하고 반영하여 학습의 속도를 빠르게 할 수 있었습니다.
Adaptive Gradient (Adagrad)
지금부터는 또 결이 다른 이야기가 들어갑니다. 앞서 설명드린 Momentum과 NAG의 경우에는 학습의 방향성을 조절하여 빠른 학습이 가능하도록 설계를 진행했습니다.
기존 SGD를 포함하여 앞서 설명드린 algorithms들은 paramter-independent learning rate를 가지고 있었습니다. 하지만 이러한 설계는 그렇게 유동적이지 못합니다. Parameter마다 update될 정도가 달라야 할 경우도 있기 때문입니다.
대표적인 예시가 sparse한 특성을 가진 data가 존재하는 경우입니다.
이 경우, zero값을 가진 데이터가 많이 등장하게 되고 objective function은 물론 gradient에 parameter가 영향을 미치는 정도가 적어지게 됩니다.
이런 과정이 매우 오래 지속된다면, 다른 parameter들은 각각의 converge에 가까워져서 learning rate를 줄이고자 했는데 sparse 한 데이터가 나타나는 parameter의 경우에는 수렴점으로부터의 거리가 아직 먼 상태인 상황이 나타날 수 있습니다.
그렇기에, Apadtive Gradient에서는 지금까지 parameter가 update된 이력을 가지고 learning rate를 결정하도록 설계합니다.
위의 식에서 G_t의 경우 paramter theta_i가 t번의 update 동안 겪었던 gradient의 square sum을 대각선 성분으로 가진 항목입니다. 즉 위 경우에는 theta_i가 겪었던 gradient의 square sum의 root성분이 분모로 가 있는 상황인 것입니다. Epsilon의 경우 처음에 분모가 0이 되는 것을 막아주는 항목입니다.
이렇게 설계를 해서 Adagrad에서 할 수 있었던 것은 paramter-dependent ㅣlearning rate design이었습니다. Update가 많이 이루어진 parameter에 대해선 수렴점과 가깝다고 판단하여 learning rate를 줄일 수 있었고, update가 적게 이루어진 parameter에 대해선 수렴점과 멀다고 판단하여 learning rate를 늘릴 수 있었습니다. 때문에 같은 update 횟수로 어느 paramter는 학습이 수렴점에 가깝게 진행되고 어느 paramter는 학습이 거의 되지 않는 경우를 핸들링할 수 있었습니다.
RMSProp
Adagrad는 parameter-dependent learning rate를 설계하는데 있어서 좋은 효율을 보여주었습니다. 하지만, 이전까지의 update를 모두 accumulate한다는 점에서 시작점과 수렴점까지의 거리가 멀면 수렴 속도가 급격하게 느려진다는 단점이 있었습니다.
Geoff Hinton은 그의 Coursera 강의에서 이를 해결하기 위한 방법으로 크게 두 가지를 적용합니다.
첫 번째로, 모든 gradient가 아닌 w개의 gradient만 이용해보자는 아이디어를 냅니다. 이를 통해서 기존의 Adagrad식에서 분모에 나타나는 항목을 전체적으로 줄이게 됩니다.
두 번째로, 그냥 square sum을 사용하는 것이 아니라 exponential decaying average를 사용합니다. 이는 평균을 내는 방식 중 하나로, 가까운 데이터에 가중치를 더 두는 형태입니다.
이 식을 sigma sum으로 펼쳐보신 분들은 아시겠지만, g_t의 square sum으로 이루어져 있는데 t가 작을 수록 가중치도 작아지는 것을 보실 수 있습니다.
이를 이용해 기존의 Adagrad에서 G_t,ii가 들어갔던 부분에 exponential decaying average를 넣어준 형태로 설계를 하는데, 이러한 설계를 통해서 전체적으로 G_t,ii가 가졌던 큰 scale을 줄이고 gradient가 사라지는 현상을 개선할 수 있었습니다. 아래는 참고로 위의 식에 대한 다른 표현입니다.
여기서 RMS는 Root Mean Square이기는 하지만 여기서의 mean이 exponential decaying average임을 기억해야 합니다.
Adaptive Delta (Adadelta)
Adadelta는 RMSProp와 비슷하면서 새로운 기능을 추가합니다.
바로 “단위에 대한 수정”입니다.
이전에 소개한 Adagrad와 RMSProp algorithms 들은 변화량에 단위가 없었습니다. Gradient에 대한 가중치를 산출할 때 gradient를 이용해서 정의를 했기 때문입니다.
Adadelta algorithm 에서는 변화량이 delta theta의 단위와 동일해야 한다고 주장했고, 이에 대한 보정으로 기존의 앞선 식들에서 eta로 사용했던 항목들을 새로운 항목으로 대체합니다.
먼저 newton’s method를 second order로 적용시보면 다음과 같은 식을 얻을 수 있습니다.
이를 약간 변형하면 다음과 같은 식을 얻을 수 있고,
분자에 있는 항은 변화량의 끝에 곱해진 g term과 일치하는 형태입니다.
그렇다면, 분자를 제외한 나머지 항목들을 앞의 가중치와 단위가 맞도록 수정을 해주어야 하는데,
분자를 제외한 나머지 항목들은 앞서 두 번째로 언급한 식에서 위와 같이 변형하여 유도해낼 수 있고, 위 항목의 우항의 분모는 현재 RMSProp의 가중치의 분모와 단위가 같기 때문에, 분자인 eta를 delta theta와 단위를 맞춰주면 됩니다.
이를 위해서 Adadelta에서는 delta theta에 대한 (변화량에 대한) exponential decaying average를 같은 방법으로 구하여 분모에 넣는 형태로 단위를 맞춰줍니다.
하지만, delta theta_t에 대한 항목은 현재 산출해야하는 값이기 때문에 t-1까지의 average만을 이용한 값으로 대체하여 구해줍니다.
사실 이렇게 단위를 맞춰주는 행위가 실질적으로 어떠한 이득을 가져오는지에 대해서 설명이 부족하긴 합니다. Adadelta 논문에서는
“Hessain Matrix provides additional curvature information useful for optimization, computing accurate second order information is often expensive”
와 같은 형태로 그들의 장단점을 표현해주고 있습니다. 이 정도로 간단하게만 짚고 넘어가도록 하겠습니다.
Adaptive Momentum(Adam)
다음으로 소개드릴 algorithm은 Adaptive Momentum입니다.
앞서 했던 표현을 잠시 다시 빌려서 쓰자면,
저희가 많이 겪는 레퍼토리이지만, 대부분의 경우에서 어떤 설계의 양극단이 가지는 큰 단점들을 적절히 보완하기 위해서 반씩 가져다가 섞는 것이 좋은 효율을 보이곤 합니다.
이런 말씀을 드린 적이 있습니다.
이와는 비슷하게 저희가 많이 겪는 레퍼토리이지만, 서로 다른 두 가지 개선 방향을 가져와 한 곳에 그 둘을 모아 모두 적용하는 것이 좋은 효율을 보이곤 합니다.
RMSProp과 Momentum의 합작을 Adam으로 소개드릴 수 있습니다.
RMSProp에서는 square gredients 들의 exponential decaying average를 구해서 전체적인 learning rate가 엄청 작아지는 현상을 핸들링 했었습니다.
Momentum에서는 과거의 gradient를 현재 gradient를 산출하는데 반영했었습니다.
이 둘을 모두 적용하기 위해 adam에서는 first momentum과 second momentum을 모두 정의하여 learning rate와 gradient 부분을 수정해줍니다.
위와 같이 first momentum m_t와 second momentum v_t를 정의하고 사용하려고 보았더니, 가중치인 beta_1, beta_2가 1에 가깝고 m_0, v_0이 0에 가까우면 초기 변화량이 0에 가까워서 학습이 느리다는 점이 있었습니다.
때문에 논문에서는 아래와 같은 bias-corrected version을 제시했습니다.
분자의 항목이 0에 가까울때 가중치 항목을 포함한 분모도 0에 가까워져 항목이 작아지는 현상을 방지해 주었습니다.
이후 앞서 설명드렸던 RMSProp처럼 second momentum 항목을 분모에 루트와 함께, Momentum처럼 first momentum 항목을 gradient 부분에 넣어 최종적으로 식을 설계합니다. Momentum의 장점인 이전 학습의 방향성을 유지할 수 있고, RMSProp의 장점인 paramter-dependent learning rate 을 gradient vanishing 없이 사용할 수 있어서 학습을 매우 빠르게 진행할 수 있다는 장점이 있습니다. 따라서 optimizer/gradient descent algorithm에 대해서 잘 모르겠으면 Adam을 쓰는 경우가 굉장히 많은 것입니다.
Adamax
Adamax는 Adam 논문의 extension에 적혀있는 gradient descent algorithm으로 주요 변경점은 Adam의 second momentum term의 L2 norm을 일반적인 Lp norm으로 확장한 것입니다.
제곱의 average의 루트에서 p제곱의 average의 p제곱근으로 변경하는 것입니다.
지속적으로 언급드리지만 average에 대한 정의는 때에 따라 다를 수 있습니다.
이 때 Lp norm은 p가 커질수록 불안정해지기 마련이라서 L1 norm 과 L2 norm이 일반적으로 쓰이고 있었는데, Adam 논문에서는 p가 무한에 가까워지는 경우에 한해서 안정성, 수렴성을 보장할 수 있다고 제시합니다.
위는 Adam의 second momentum에 Lp norm을 적용한 식입니다.
위는 Lp norm의 수렴성을 증명한 것입니다.
첫 번째줄에서 두 번째줄로 넘어가는 것은 간단한 과정이니 설명을 생략하고, 두 번째줄에서 세 번째줄로 넘어갈 때는 앞의 항목이 p를 무한대로 보냈을 때 1로 수렴하기 때문에 제외하고 남은 것을 p승으로 묶은 것입니다.
세 번째줄에서 네 번째줄로 넘어갈 때는 maximum norm의 경우로, 괄호 내부에 있는 항목들 중 maximum 값을 g_max라 하면 g_max로 모든 항목을 바꾼 것보다는 작고, g_max를 하나만 둔 것보다는 크기 때문에 이 둘 사이에 값이 존재해야 하며 이는 극한을 보냈을 때도 예외가 아닌데, 두 값 모두 극한으로 보냈을 때 g_max 이므로 값이 g_max로 수렴한다는 것을 증명할 수 있습니다.
위의 식을 본 논문에서는 다음과 같이 변형해 표현합니다. Beta_2*v_t-1 항목이 앞선 max내부의 g_t를 제외한 나머지 항목들을 포함한다고 보시면 됩니다. (전개를 하기 전의 버전으로 보시면 됩니다.)
바뀐 norm 을 기존 norm의 자리로 대체해주면 위와 같은 식이 됩니다. Adam과 다른 점이 있다면 이렇게 바꿔줌으로써 max operation만으로 u_t를 정의하기 때문에 가중치인 beta_1, beta_2가 1에 가깝고 m_0, v_0이 0에 가까워도 bias-correction 없이 gradient가 초기에 유지될 수 있다는 장점이 있습니다.
Nesterov Accelerated Adaptive Momentum (NAdam)
Adam에서 Momentum과 RMSProp을 섞어 이전 학습의 방향성을 유지할 수 있고, paramter-dependent learning rate 을 gradient vanishing 없이 사용할 수 있다고 말씀드린 적이 있습니다.
그런데, 저희가 방향성에 대한 고려를 하면서 과거와 현재, 그리고 미래의 방향성까지 고려를 했었는데 Adam에는 그것까지 고려가 되어 있지는 않습니다. 미래 학습의 방향성을 미리 고려하는 설계는 진행되어 있지 않은 것입니다.
이쯤되면 눈치채셨을 수도 있으셨겠지만 NAG와 Adam을 섞은 설계, NAdam에 대해서 소개드리려고 합니다.
먼저 Momentum을 다시 상기해 봅시다.
위의 식을 앞서 보신 적이 있으실 겁니다. 이를 이용해,
위와 같은 식으로 최종적으로 마무리 했었습니다.
다음으로 NAG를 다시 상기해 봅시다.
여기서 NAdam은 과거의 momentum을 누적시켜온 이 방식을 유지한 채 m_t로 작성한 NAG의 마지막 식을 m_(t+1)을 사용한 효과를 내기 위해서 다음과 같이 변형합니다.
여기서는 m_t을 m_(t+1)로 변경하는 효과를 냈다는 사실에 주목해 주시면 좋습니다. (eta*g_t+1 항목은 만들 수 없기에 eta*g_t로 둔 것입니다.)
다음으로 Adam을 다시 상기해 봅시다.
위의 식들을 이용해 최종적으로 식을 전개해보면,
위와 같고 다시 bias-correction 식을 이용해 식을 바꿔보면,
위와 같습니다. 이후 m_(t-1)을 m_t로 바꾸어주어 아까 말씀드린 미래의 momentum에 대한 효과를 반영해주면,
최종적으로 위와 같은 식으로 정리해볼 수 있습니다.
Nadam은 Adam에 존재하지 않았던 미래의 학습 방향성을 미리 예측하여 고려하고 반영할 수 있다는 장점이 존재합니다.
Conclusion
글도 길고, 내용도 많아 정리가 안되실 분들을 위해 제가 몇 가지 중요 사항들을 정리해드리겠습니다.
가장 먼저, BGD, SGD, Mini-Batch GD에 대해서 살펴보았었습니다. 이들은 objective function이 정의되는 데이터셋의 범위에 따라서 형태가 달랐었고, 학습 속도의 SGD와 학습의 정확성 BGD(local minima에 빠지지 않는 등)의 trade-off로 최종적으로 Mini-Batch GD를 소개드렸습니다.
다음으로 학습의 방향성을 조절할 수 있는 Momentum, Nesterov Accelerated Gradient에 대해서 살펴보았었습니다. 이들은 각각 과거의 gradient를 이용, 미래의 gradient를 예측하여 현재의 gradient 산출에 반영하는 형태였습니다. 이를 바탕으로 학습의 속도를 빠르게 할 수 있는 방법의 결이 늘어났었습니다.
다음으로 학습의 스텝 사이즈를 조절할 수 있는 Adagrad, RMSProp, Adadelta에 대해서 살펴보았었습니다. 이들은 기본적으로 parameter-dependent learning rate를 설정할 수 있도록 하는 방법들이며, RMSProp에서는 gradient vanishing 문제를, Adadelta에서는 unit에 대한 보정을 진행하여 각각 학습에 개선을 진행했었습니다.
마지막으로 학습의 방향성과 학습의 스텝 사이즈를 모두 조절할 수 있었던 형태인 Adam, Adamax, Nadam에 대해서 살펴보았었습니다. 이들은 Momentum과 RMSProp을 합쳤던 Adam에서 학습의 방향성과 스텝 사이즈를 모두 고려한 것을 바탕으로 개선사항을 만들어낸 것들입니다. Adam에서 second momentum을 L_infinity norm으로 변경한 Adamax에서는 bias-correction없이 학습을 진행할 수 있으며 Adam에 NAG를 합쳤던 Nadam으로 미래의 학습 방향성도 추가로 고려할 수 있었습니다.
이 글을 읽으신 여러분들, 이 글의 처음으로 돌아가 썸네일 사진을 다시 한 번 돌아보시고 차근차근 정리해보시면 도움이 많이 되실 것 같습니다.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.wordpress.com/2021/01/16/paper-review-gradient-descent-algorithms/


