Reinforced Learning — “Techniques, Applications and benefit over Deep Learning”
Original Source Here
Reinforcement Learning — “Techniques, Applications and Benefits over Deep Learning”
With an always progressive era of Artificial Intelligence (AI), many scientists/researchers have believed that the need of machine learning (ML) and deep learning (DL) will increase ten folds in a year. While AI is the Umbrella term for the ML or DL, but ML/DL in turn behaves as an umbrella for various technologies.
Artificial Intelligence refers to the technology where a device exhibit human-like intelligence, decision making skills. Machine Learning and Deep Learning are the two major domains of AI. ML pays attention to making a machine learn by its own experiences and DL makes use of neural networks to make this learning system more progressive and efficient. The pictorial representation of the same can be as shown:
Coming to the inner-most domain of the AI, or in short, the most accurate one. Deep Learning takes the advantage of layers present in a neural network to make algorithms which are inspired by a human brain. Deep Learning filters the information as it is filtered by a human brain, so most of the applications of the deep learning techniques are in the domains of what humans generally do. Most common examples are auto-pilot cars, computerised surgeries etc. The Deep Learning algorithms are made to learn the differences between various different constraints, and act accordingly.
Today, we wish to discuss about an important technique of Deep Learning domain and that is “REINFORCEMENT LEARNING”.
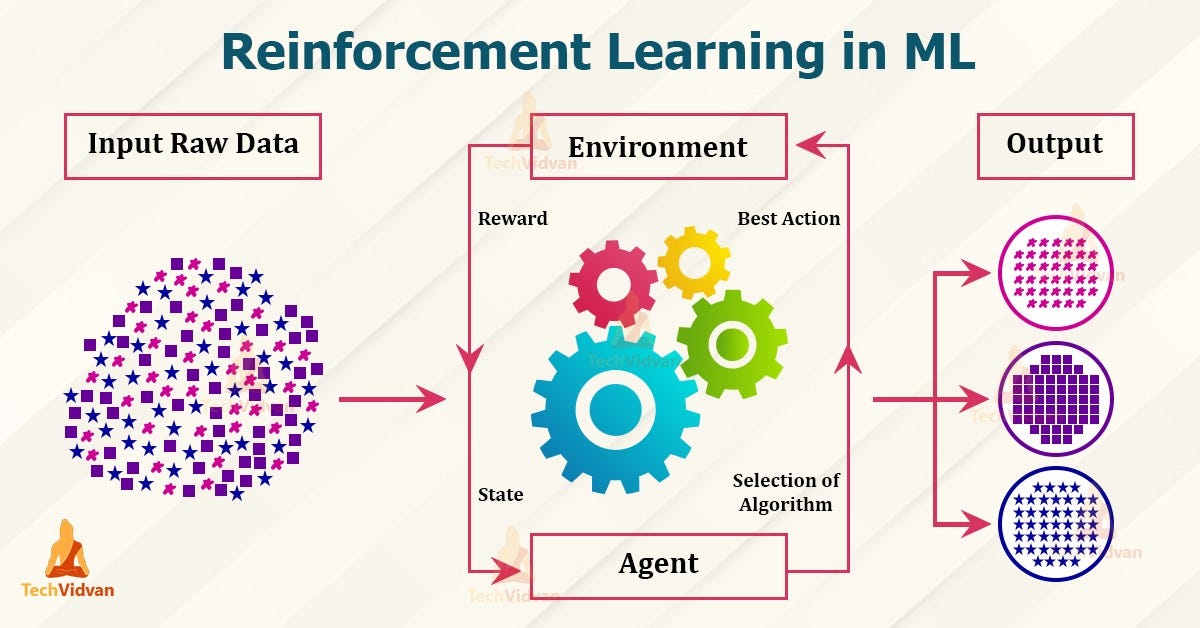
Reinforcement Learning or RL, is a sub-domain of DL, which works upon making a sequence of inferences one after another and get rewarded for each decision. It is a group of context-based decision-making algorithms. The machines are trained over these algorithms through a reward-based mechanism. It is mainly a goal-oriented technique, the main objective of which is to attain a complex yet achievable goal and maximize this goal over time, by re-run of the algorithm again and again. The major component of any RL technique are,
– AGENT
– Action
– Rewards
– Environment
– States
– Observations
– POLICY
Let us describe each one of them in short before moving further,
An Agent can be a software program/algorithm, which takes a decision on behalf of the machine. For example- a) in the case of a walking robot, agent is a program which controls the robot; b) in the case of a problem of adjusting temperature in automatic or sixth sense air conditioners, agent can be a thermostat. Agent has the duty to take a decision in the environment in which it is currently present. It learns by “Trial-and-Error” method. And, the objective of the Agent is to maximize the Rewards.
An Action is the set of some fixed moves which an agent can take to move from one state to another. This set of moves always abide by the rules of the environment. An agent can add more actions on the basis of its observations. An action can be denoted by ‘a’ while a group of actions can be denoted by ‘A’. So, ‘a’ is the action an agent can take in the current situation to make a move, while ‘A’ is the group of all possible moves. ‘A’ can be limited to as less as one or two actions, for example, when we play a game, we can only move left or right, and ‘A’ can be as complex as handling a satellite communication through space.
A Reward is the outcome of the environment in which the agent is taking some actions. In Reinforcement Learning, output is generally given in the form of rewards. These rewards can be “POSITIVE” or “NEGATIVE”, depending upon the type pf environment. For example: in the case of a sixth sense air condition a positive reward can be considered when the action taken by sixth sense technology for maintaining adequate temperature meets the need of the human, while a negative reward will be considered when the human have to update the temperature, even when the sixth sense is working on the same. In the case of a puzzle maze, the rewards can only be negative for every turn, and the responsibility of the agent is to minimize the moves, so that result should be less negative reward.
An Environment is a group of functions that convert the current state of the system to the next state based on the actions taken by the Agent. This environment also provides the reward to the agent. How this environment works is some sort of black boxing, the details of which are not known to the agent. The agent only gets to know the output in some way of rewards or feedback. And, on the basis of these the agent tries to maximize the rewards.
Let us have an environment of the Pac-Man game simulation, here agent will be a program which controls the Pac-Man. The actions would be the nine possible shift positions of the Pac-Man, that is up, down, left, right etc., and the agent will be rewarded in the game points.
Another simple example of reinforcement learning can be by a human to train his/her dog for some simple tasks, like standing on his two legs, fetching a toy etc. Here, a dog is an agent who knows some actions and human, the environment which rewards the dog on successful competition on any task. Initially, for his every action the environment rewards the dog with food or hug. After some time, the dog starts improving to get more and more rewards. Here the observations of the environment(human) also plays an important role, if environment observes he can increase the complexity level, he can do so by increasing the rewards or getting new rewards.
A State is the scenario in which an agent finds himself. The task of the agent is to take an action to create a move to the next state. This new state will result in the rewarding of the agent with positive or negative value.
An Observation can be any small detail which makes the environment increase or decrease the complexity of the system, and thus helping the agent to maximise the rewards.
A Policy, is the algorithm used by an agent to adhere its actions to the rules of the environment. In basic words, a policy can be a neural network which takes observations of the environment as the input and provide actions as the result.
REINFORCEMENT LEARNING TECHNIQUES
There are many algorithms available for reinforcement learning, which are categorised on the basis of two main concepts:
Ø Model-based or Model-free
Ø Policy-based or Policy-free
Model-based RL algorithms uses a model to learn about the experience of the past actions, and transition from the last state to the current state, while model-free algorithms are based on “Trial-and-Error” method of taking action.
Policy-based RL algorithms works on the policy set by the environment or the agent, while policy-free takes the policy of some existing approach and use it as their own.
The major techniques which we use for RL are:
Ø General Model: Cartpole method
Ø Markov Decision Process: Dynamic Programming, Monte-Carlo Simulation
Ø The Temporal Differences Method
Ø Q-learning
General Model
The behaviour of an agent is guided by the past experiences. And the collection of this experience is calculated by a “cost estimator”. This estimator calculates the cost of learning new experiences. In this model, the agent is equipped with sensors to make the observations, and learn new experiences. These observations are merged with past knowledge of the environment and then fed to an algorithm called as “state estimator”, with the help of which a vector is maintained. This vector is required to differentiate between the expected output and original output. The difference is then tried to be optimized by the agent by making new observations and take actions to maximize the rewards. The General Model is a three-step process:
1. Agent makes an observation and perceive the information provided by the environment.
2. Agent then takes an action depending upon the observation and the past experiences.
3. Agent reinforces the new observations and updates its experiences matrix.
General Model: Cartpole Problem
This model is very well explained by “Cartpole Problem”. In cartpole problem, the objective is to find a policy of appropriate actions such that a pole can be balanced over a cart for as long as possible in a given environment. The actions are the force applied to the cart in the form of PUSH and PULL operations, mostly known as “bang-bang control operations”. The environment is a matrix of limited area and actions are taken on the basis of current situation of the pole.
The variables which handle the problem are:
x — represents the offset of the cart, from the centre of the matrix.
x’ — linear velocity.
Ɵ — the angle of the pole with respect to the centre of the cart.
Ɵ’ — angular velocity.
At any time t, agent checks the values of all variables of the set(x,x’,Ɵ,Ɵ’), and takes the action as per the observation and reinforces the observation if gets a zero as the output. At the end, it updates the values in the cost estimator, as per the observations made and rewards earned.
Markov Decision Process
This whole method is dependent on a condition called as “Markovian Condition”, which says that, for every observation o made by an agent, the observation should be made up of last observation and action only i.e.
Ot+1 = f(Ot , at, wt) [1]
Where Ot is the last observation made by the agent, at is the last action taken by the agent, and wt is the disturbance.
If the agent can observe all the states as per the condition [1], then this condition is called as markovian condition, but if it fails to observe all the states as per the above rule, then it is called to be exhibiting non-markovian condition.
Let us solve the Markov decision process problem. Let us have:
I. A finite set of all the possible actions, a A.
II. A finite set of all the possible states, x X.
III. Time-based probabilities, P(xt+1|xt , at).
IV. A finite set of reinforcements r(x,a) ꭆ
The task of the agent is to minimize the cost function.
There can be two ways in which a Markov Decision Process can be solved:
1. Dynamic Programming
2. Monte-Carlo Simulation
Markov Decision Process: Dynamic Programming
We can solve the above-mentioned stochastic problem by using basic dynamic programming principals. Let us have a look at some of the operators and theorems available in dynamic programming:
Operators:
· The Successive Approximation Operator TΠ :
For Π: X → A
For V: X → R
· The Value Iteration Operator T:
For V: X → R
Theorems:
· Bellman Optimality Equation: V* = TV* [4]
· For any arbitrary bounded function, the optimal cost can be found out by
· If the policy is fixed, the optimal cost can be found out by:
· The Value Iteration Method:
· The Policy Iteration Method:
Markov Decision Process: Monte Carlo Simulation
There are many shortcomings of the dynamic programming which makes it difficult to be used with reinforcement learning, the major one is that dynamic programming requires a model, and usually always have a goal of optimized solution beforehand. We can make a transition from dynamic programming to reinforcement learning by providing a simulator which makes DP behave as a model and safely ported to work upon RL. This simulator is called as Monte-Carlo simulator. And, this transition can be easily calculated by Robbins-Monro Procedure:
Temporal Differences Method
This method is the base of every RL technique. It takes the equation of Robbins-Monroe, as shown in [10], and then expand it to this:
Adding, subtracting and expanding, leaves us with this:
Here, the difference with respect to every time, is called a Temporal Difference. The temporal difference is the difference between expected cost and actual cost at any moment of time ‘t’. So, this is a method to calculate the expected cost, but for reinforcement learning, we wish to optimize the expected after each and every action. This makes us to move to the next technique, which is the most popular RL technique “Q-Learning”.
Q-Learning
It is an iterative method for making learning a continuous process on the basis of actions and policy. So, the Q-learn function, which is based upon action and policy, defined as a set of these two attributes: Q(x, a)
Q-Learning algorithm can be defined as follows:
1. Visit any state xi and select any action ai.
2. While you are in the current state, receive reinforced data from previous state, and generate reinforcement data for the future state.
3. Update the value of the action taken in Q(xt, at) for that particular time ‘t’.
Characteristics of Reinforcement Learning:
1. No need of any supervisor to check on the learning process.
2. Real Reward system is used to make the agent greedy, and rewards are both positive or negative to make the agent more and more greedy.
3. Decision making is usually done sequentially.
4. Each action derives a reward, either positive or negative.
5. Feedback can also be used in place of rewards.
6. Agent’s actions determine the success rate.
Real-life Applications of Reinforcement Learning:
1. Robotics
2. Game-Playing
3. Natural Language Processing
4. Computer Vision
5. Machine Learning
6. Data Processing
7. Industry Automation
8. Training Systems
9. Controlling Auto-pilot vehicles
10. Auto Trading software
11. Healthcare
Robotics: Agent — Program which controls the robot
Environment — Real World
Action — Sending signals
Rewards — Positive/Negative
Pac-Man: Agent — Program controlling Pac-Man
Environment — Simulation of the game
Actions — Nine possible joystick positions
Observations — Screenshots
Rewards — Game points
Thermostat: Agent — Thermostat
Environment — Real World
Action — sensing the temperature and adjusting as per weather
Rewards — Positive, whenever the temperature is close to the target temperature. Negative, if the human has to maintain the desired temperature.
Auto-Trader: Agent — Observes the stock market
Rewards- Monetary gains
Controlling Auto-pilot vehicles: Agent — program that controls the vehicle
Environment — Real-world
Action — Speed control, avoid collision with other vehicles, drive at correct side of road, making the turns.
Rewards — reach safe at the destination
Healthcare:
Challenges to Reinforcement Learning:
1. Feedback/Reward System can be very tedious, time consuming, and also can be a challenge to implement because some very easy looking systems can have a difficult to manage feedback/reward system.
2. These parameters can make a RL system slow.
3. Observations may not be accurate each time, partially correct observations will give us negative rewards.
4. Overload of reinforced data may result in incorrect state transitions.
5. Policy making can be a huge challenge.
6. Real-world is a dynamic environment.
Real life applications of RL which cannot be solved with DL:
Deep learning uses a series of layers to analyse the data, and learn new things from that data. It can be supervised or unsupervised in nature. The models/techniques used in deep learning automate the learning process through multiple layers present in neural network but reinforcement learning is inspired by the psychology of living things. The reinforcement learning comes into picture when we can neither use supervised or unsupervised mode of learning. The answer may or may not be correct each time, but the agent learns something new with each action.
Some of the real-life applications which we can only solve with reinforcement learning and not by deep learning are:
1. Training a dog: we have shown in this article earlier also, that a dog can be trained if we keep him rewarding with treats, after his every move.
2. Walking infant: an infant learns walking only by himself, we can only tell him but we cannot make him learn, unless he tries himself. We cannot create a model in deep learning which can make an infant walk, it can only be learned over time, by experiencing falling and failing.
3. Eating a fish: we cannot create an algorithm to make a human learn to eat fish, by removing the bones. The human learns by reinforcing the past experience with the current situation.
4. Stock Trading: in the dynamic world of stock, one can not make a program to correctly predict the stock which will rise in future, it can only be learned over-time.
By rewarding, RL makes sure that these applications can keep on gaining experiences and keep on applying reinforced data.
So, Reinforced Learning makes use of rewarding facility to make some learnings which can not be done via deep learning algorithms.
REFERENCES
1. https://deepsense.ai/what-is-reinforcement-learning-the-complete-guide/
2. https://en.wikipedia.org/wiki/Deep_reinforcement_learning
3. https://wiki.pathmind.com/deep-reinforcement-learning
4. “A STUDY OF REINFORCEMENT LEARNING APPLICATIONS & ITS ALGORITHMS”, Kumar Gourav, Dr. Amanpreet Kaur, IJSTR, Vol. 9, Issue 03, ISSN 2277–8616
5. Figure 4 https://www.kdnuggets.com/2019/10/mathworks-reinforcement-learning.html
6. Figure 7 https://techvidvan.com/tutorials/reinforcement-learning/
7. Figure 9 https://neptune.ai/blog/reinforcement-learning-applications
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/06/09/reinforced-learning%e2%80%8a-%e2%80%8atechniques-applications-and-benefit-over-deep-learning/


