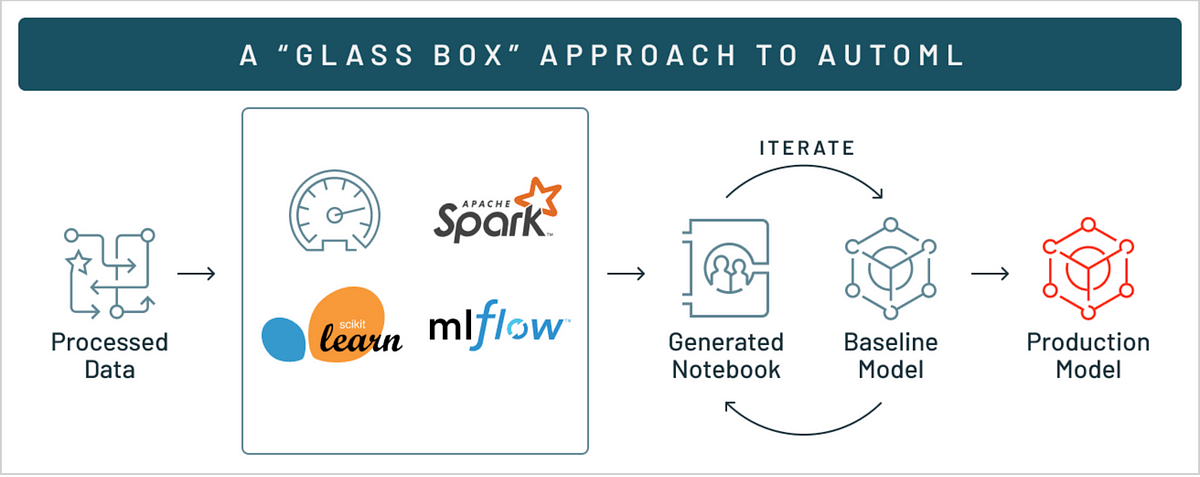
Automate Machine Learning using Databricks AutoML — A Glass Box Approach and MLFLow
Original Source Here
- Next, we need to select the evaluation metric — F1 score (Because the data is imbalanced).
- We can even configure the stopping criteria — time out and a number of trail runs in the advanced configuration settings.
- After setting all the configurations, click on “Start AutoML” to train different iterations of the classification algorithms.
Exploring the notebooks generated by AutoML
Now that an hour has been passed, AutoML has completed executing different combinations of model iterations.
- If you take a close look at the metrics, they are automatically sorted by the validation
f1_scorein descending order such that the best model is at the top of the table.
AutoML is integrated with MLflow to tracking all the model parameters and evaluation metrics associated with each run. MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry[1].
MLflow makes it easy to compare two or more model runs and select the best model run among these for further iteration or pushing the model to production.
Data Exploration in AutoML
Before we take a deep dive into the model execution runs, Databricks AutoML creates a basic data exploration notebook to give a high-level summary of the data. Click on the view data exploration notebook to open the notebook.
Without properly understanding the data, how many advanced algorithms we use on the data to build models it might not give appropriate results. So data exploration is a very important phase in machine learning but it is a time taking process most of the time data scientists will skip this phase.
Databricks AutoML saves time by creating the baseline data exploration notebook, data scientists can edit this notebook to expand on the data analysis techniques.
Internally AutoML uses pandas profiling to give information about correlations, missing values, and descriptive statistics of the data.
Exploring the AutoML Run Notebook
Now that you have a good understanding of the data after going through the data exploration notebook and you want to look at the AutoML model building code.
Databricks AutoML displays the model results and provides an editable python notebook with the source code for each trial run so that we can review or modify (eg: create a new feature and include that in the model build) the code. Under the source column on the experiment home page, you will see the reproducible notebook for each trial run — that is why it is called a Glass Box Approach (Allows you to look under the hood).
In order to open the source code for a run, click on the notebook icon under the source column for that run.
Each model in the AutoML runs is constructed from open source components, such as scikit-learn and XGBoost. They can be easily edited and integrated into the machine learning pipelines.
Data scientists or analysts can utilize this boilerplate code to jump-start the model development process. Additionally, they can use their domain knowledge to edit or modify these notebooks based on the problem statement.
Registering the model to the model registry
Before we can deploy our model for serving, we need to register the model in the MLflow model registry.
Model Registry is a collaborative hub where teams can share ML models, work together from experimentation to online testing and production, integrate with approval and governance workflows, and monitor ML deployments and their performance[2].
To register a model on the model registry click on the run of your choice (my choice is the best run i.e.. the top run) and scroll down to the artifacts section & click on the model folder.
- Click on the Register model, select create a new model and enter the model name.
- You can register all the relevant models (models predicting quality of red wine) under the same name for collaboration (sharing models across different teams)
Now that we registered our model into the model registry, click on the popup icon located at the top right corner of the artifacts section to open the model registry user interface.
Exploring Model Registry
The model registry provides information about the model, including its author, creation time, its current stage, and source run link.
Using the source link you can open the MLflow run that was used to create the model. From the MLflow run UI, you can access the source notebook link to view the backend code for creating the model[3].
- You can even edit/add the model description for the model. Remember that the model description is dependent on the model version.
- Stages: Model Registry defines several model stages: None, Staging, Production, and
Archived. More on this in the next section.
Deploy the model using REST API
We are in the final section of this tutorial. In this section, we will discuss how to push the model into production and serve the model using REST API.
Changing Model Stage
- As we have seen in the previous section about different stages in the model registry. Each stage has a different meaning.
- For example, Staging is meant for model testing, while Production is for models that have completed the testing or review processes and have been deployed to applications.
- In order to change the stage of a model, Click the Stage button to display the list of available model stages and your available stage transition options.
In an enterprise setting, when you are working with multiple teams such as the Data Science team and MLOps team. A member of the data science team requests the model transition to staging, where all the model testing takes place.
- All the tests are done, the model will be transitioned to the production environment for serving.
In this tutorial, I will directly push the model to production for simplicity. To push the model to production, Select Transition to -> Production, enter your comment, and press OK in the stage transition confirmation window to transition the model to Production.
- After the model version is transitioned to Production, the current stage is displayed in the UI, and an entry is added to the activity log to reflect the transition.
- To navigate back to the MLflow model registry main page, click on the model’s icon on the left sidebar.
- MLflow Model Registry home page displays a list of all the registered models in your Azure Databricks workspace, including their versions and stages.
- Click the redwine_qualitymodel link to open the registered model page, which displays all of the versions of the forecasting model.
- You can see from the above image, there is a model “Version 1” is in the production stage.
Model Serving
Model serving in Databricks is performed using MLflow model serving functionality. MLflow performs real-time model serving using REST API endpoints that are updated automatically based on the availability of model versions and their stages.
- To enable serving, click on the serving tab present in the redwine_qualitymodel model registry page.
- If the model is not already enabled for serving, the Enable Serving button appears.
- When you enable model serving for a given registered model, Azure Databricks automatically creates a unique cluster for the model and deploys all non-archived versions of the model on that cluster[4].
Predictions using Served Model
- After you enable the serving, it will take a couple of minutes for the serving cluster to be enabled. Once it is enabled you will see “ready” status.
Testing Model Serving
- After the serving cluster is ready, we can validate the model response by sending out a request in the request tab and view the response.
- In order to send a request, we need some sample data points. Click on the show example tab, it will automatically populate 5 data points and click -> send request to view the response.
Model URL
- On the serving page, you will see the model URL endpoints, Use these endpoints to query your model using API token authentication.
For more information (code snippets) on serving using REST API, check out the serving documentation.
Cluster Settings
- By default, databricks will assign a basic instance type to the serving cluster. But if you are working on a very large dataset, you might need a more powerful cluster to handle the volume of predictions (responses) in real-time.
- To change the cluster settings, go to cluster settings and change the instance type based on your usage and click save.
- It is important that you don’t confuse this cluster with the cluster we created when setting up the AutoML experiment.
– Serving Cluster: Cluster associated with serving endpoint.
– Databricks Cluster: Cluster associated with executing AutoML/Spark.
Note:
- The serving cluster is maintained as long as serving is enabled, even if no active model version exists.
- As long as the serving cluster is maintained, you will be charged as per the configuration of the instance that you selected for serving.
Remember to stop both the clusters before you log out from your azure account.
- To stop the serving cluster, click on the stop button next to the status on the serving page.
- To stop the databricks cluster, go to the clusters page by hovering the mouse on the left bar and select the cluster & click terminate.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/06/11/automate-machine-learning-using-databricks-automl%e2%80%8a-%e2%80%8aa-glass-box-approach-and-mlflow/


