Introduction to LSTM and GRU
Original Source Here
Introduction to LSTM and GRU
Compared to traditional vanilla RNNs (recurrent neural networks), there are two advanced types of neurons: LSTM (long short-term memory neural network) and GRU (gated recurrent unit). In this blog, we will give a introduction to the mechanism, performance and effectiveness of the two neuron networks.
Gradient
In standard RNNs, sigmoid or hyperbolic tangent activation function is generally used as an activation function. There are large areas of each function where the derivative is very close to 0, which means the weight updates are small, and RNNs get saturated. When the values of gradients are are extremely low or high, it is called vanishing gradient or exploding gradient, respectively. LSTMs and GRUs can help the models avoid these problems such as vanishing and exploding gradients when working with large sequences of data. By constantly updating their internal state, they can learn what is important to remember, and when it is appropriate to forget information.
LSTM
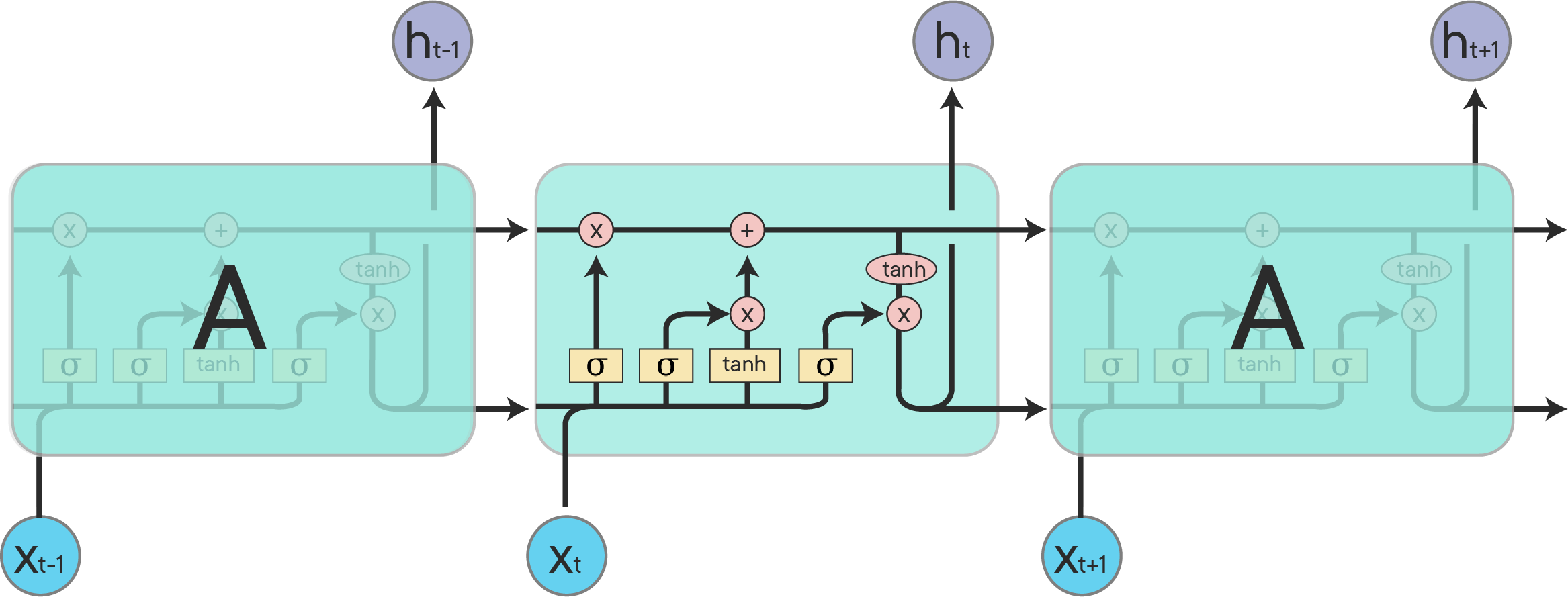
There are three gates in the structure of LSTM: an input gate to determine the amount of the cell states that were passed along should be kept, a forget gate to determine the amount of the current state should be forgotten and an output gate to determine the amount of the current the current state should be exposed to the next layers. The diagram of a LSTM cell shows how the information flows through from left to right, and where the various gates are for each function performed.
There’s no good answer yet as to whether GRUs or LSTMs are superior to one another. In practice, GRUs tend to have a slight advantage in many use cases, but this is far from guaranteed. The best thing to do is to build a model with each and see which one does better.
AI/ML
Trending AI/ML Article Identified & Digested via Granola by Ramsey Elbasheer; a Machine-Driven RSS Bot
via WordPress https://ramseyelbasheer.io/2021/04/04/introduction-to-lstm-and-gru/


